The Phobia List provides an exhaustive list of phobias. Although it is difficult for many of us to understand or relate with many of these phobias, some are all too easy or me to understand. For example, I fear that I suffer at least mild cases of demophobia (fear of crowds) and homilophobia (fear of sermons). However, one fear that I see with a relatively high degree of occurrence in the software development community is the seemingly irrational (to me) fear of SQL.
The fear of SQL is so rampant that Ritesh Shah has named his blog "Fight the Fear of SQL." Other posts/comments indicating the prevalence of this fear of SQL include a Ruby on Rails related comment, a .NET related blog post, and in this Hibernate versus iBatis presentation (Java).
There have been numerous attempts at abstracting away or hiding SQL from the developer. The object-relational mapping (ORM) approach is probably the largest of these efforts in terms of person hours invested. This approach attempts to allow developers to focus on objects and their mappings to relational database structures (such as tables and columns) with the hope that the developer will never (or at least much less often) have to read, write, or maintain SQL.
Early Enterprise JavaBeans (EJB) container-managed persistence [CMP] (and especially container-managed relationships [CMR]) was a disaster by nearly all accounts. Not only was it more difficult (for most of us) to use than using SQL directly, but its (EJB 2's) EJB Query Language looked and felt suspiciously like SQL made worse by embedding it in XML. In fact, it's my contention that the much easier-to-use Java EE 5/6 with JPA is as popular as it could be because of these highly memorable negative experiences with its predecessors.
Another ORM example that was received much better in the Java community is Hibernate. Hibernate and the Spring Framework became a very common (if not THE most common) stack for Java-based applications at least in part because they were perceived as being easier to use than SQL/JDBC and J2EE. However, not everyone loves Hibernate as evidenced with posts such as Hibernate is crazy, iBATIS is awesome.
Overall, I'm a fan of JPA as I hope I made clear in my article Basic JPA Best Practices. I like the ability to relatively easily tie my normal Java objects into the transaction support of the supporting application server. Also, I think its advantageous to have a standardized approach to ORM rather than using a proprietary solution such as pre-JPA Hibernate. With all the positives of JPA, I still find there are times when it either is more than I need or when the impact it has on my object design is too great to justify. Furthermore, I have found the ability to be able to read SQL invaluable in debugging problems with my code that uses JPA implementations. In other words, I still need to know and be comfortable with SQL, even when using JPA implementations.
There are situations where even the best ORM implementation introduces more trouble and requires more effort than using SQL directly (such as via JDBC) or using a less intrusive technology (such as iBATIS). This seems to be especially true for complex data structures or for data designs that do not fit "the norm." Ted Neward has referred to object/relational mapping as the Vietnam of Computer Science. Aldo Cortesi's post A Farewell to ORMs provides excellent coverage of his moving away from use of ORMs in Python.
Regarding ORMs, Tim Bray has written, "ORM Blecch: My relationship with relational databases has always been chilly, but that’s a lot better than my relationship with object-relational mapping, which has never given me anything but pain. The one route to unambiguous success in ORM seems to be the Rails’ tactic of slashing flexibility."
I recall an interesting keynote Tim Bray gave at Colorado Software Summit 2004 where he basically asserted that we're all paid enough, trained enough, and smart enough to be able to work with SQL without need for an ORM. The interesting this is that wasn't even the point he was trying to make. He was actually trying to say the same thing for object-to-XML mapping and was using ORM almost as a given as a thing we don't always need. Mike Keith has provided a more thorough summary of this keynote and some good counter arguments. This keynote caused Mike to start writing a blog!
ORMs are a huge, but not the only, example of trying to avoid using SQL. Other examples include efforts like Java Data Objects (JDO), object databases, and XML databases. JDO had some promise but its future largely ended with what it contributed to JPA. Early on in my career, I used an object-oriented database called Versant that I actually really liked, but in general object-oriented databases have not taken much of the market share from relational databases. Similarly, XML databases already seem to have peaked without coming anywhere near the popularity of the relational database.
A very popular (in the blogosphere) alternative to SQL these days is the NoSQL concept. When I first read this term, my initial reaction was a rolling of the eyes and thinking "Here we go again." The name NoSQL is a little bit of a misnomer. If all it was about was not needing to use SQL, I would dismiss it immediately given the many available alternatives to SQL and to the fact that SQL itself is just not that difficult. I don't know much about NoSQL, but the thing that prevents me from immediately dismissing the notion is the primary cited motive for NoSQL. Despite the poorly chosen name, NoSQL really seems to be about moving away from the relational database rather than simply not using the Structured Query Language. That may or may not be a good idea and the alleged scalability benefits of NoSQL might be debated, but at least it's not grounded in the irrational fear of SQL.
Where does this irrational fear of SQL come from? I actually have experienced this myself. My undergraduate degree was in electrical and computer engineering. Although I took several computer science courses as part of my computer emphasis, there were some classes I did not get to take in the CS department. One general area I did not get any exposure to was SQL. In my first job out of college, I was somewhat intimidated by just the talk of SQL. However, one of my first projects had me working with SQL on a regular basis and I soon learned that it wasn't so bad.
Today, I have spoken with very bright, talented young developers who maintain nasty ORM mapping files with no problem, but fear that they cannot learn SQL/JDBC. I try to explain to them that the SQL is no more difficult than the mappings they are endeavoring to maintain, especially in the cases of "weird" or complex data needs. They fear the unknown.
There are real issues with SQL. Perhaps the biggest for me is the lack of any truly implemented standard. Some might argue that there is a SQL standard, but I have come to believe that a standard is only as good as its implementations. If the major and popular implementations poorly implement the standard or ignore it altogether, most of the value of having a "standard" is forfeited (it's not really standard in that case). Design patterns such as the Data Access Object were created to deal with this, but there is no question that Rails and ORMs that provided migrations capabilities have the upper hand here. In situations where multiple database vendors are used or are likely to be used, the lack of standardization in SQL can make its use truly scary.
Another commonly alleged drawback to SQL is that it requires learning different syntax and semantics than the programming language being used with SQL. This would be a bigger issue to me if basic SQL was as complex as learning the basics of a new programming language. In fact, I have benefited more than once from having the commonality of SQL to lean against while writing a database access piece of code in a new programming language. For example, it was pretty easy to learn how to apply Ruby to my database needs because of my knowledge of SQL.
In a world where polyglot programming is the trend and many believe it wise to be comfortable with at least one statically typed language and one dynamically typed language, it seems obvious to me that it's in the best interest of developers to gain some degree of comfort with SQL as well. It's still one of the most likely languages a developer will actually use in his or her career. The side benefit of becoming more comfortable with SQL is that comfort and familiarity will often drive out the irrational fear.
Software developers are (typically) too well-trained to limit themselves due to fear. The best software developers are able to think critically about their architectures, designs, and implementations and about their choices of languages, products, libraries, and frameworks. JPA implementations have provided exactly what I need in many situations. However, JDBC/SQL implementations (especially with Spring) have also been my best bet in several cases. When one removes irrational fear, one can make the correct choice for the situation. With irrational fear present, one's ability to choose correctly is significantly impeded.
I have tried to come up with a witty name of the phobia describing the irrational "fear of SQL." Sequelphobia seems to already be taken for fear of movie sequels ("The Empire Strikes Back" might cure that) or video game sequels. Because fear of SQL is often correlated with not knowing SQL, I thought about xenophobia, but that has a negative cultural/political emphasis that I don't want to drag into this discussion. For now, I'm going to go with calling it "Sqlphobia." I welcome suggestions for a better name.
Basic SQL is not that difficult. I have seen DBAs and people with far more SQL experience than I have do amazingly tricky and complex things with SQL, but I find that simple SQL covers a large percentage of my needs. JDBC makes using SQL much easier than it used to be with proprietary approaches such as Pro*C/C++ precompiler and Spring+JDBC makes use of SQL even easier. The .NET community and other language/platform ecosystems typically have similarly easy-to-use SQL support as well.
In the end, I don't believe that straight JDBC/SQL is the best choice for every project. Some of the alternatives mentioned here are superior choices given certain conditions. However, I do think that an irrational fear of SQL is demonstrated when one spends much more time shoehorning a non-SQL solution into a place where it doesn't fit well simply to avoid having to use SQL.
Monday, March 29, 2010
Tuesday, March 23, 2010
(Free) Ruby Best Practices (PDF) Book
In a recent daily perusal of DZone headlines, the link Ruby Best Practices free ebook caught my attention. This link takes one to the Ruby Best Practices - Book site, where the PDF can be downloaded free of charge or registration by start reading (free PDF). The same page also has links to the related blog, to a github repository of the book's source code, and to purchase a hardcopy of the book.
As is the case for most "Best Practices" books, this one is probably more attractive to those who are not completely new to Ruby. For the developer who is completely new to Ruby, the famous Programming Ruby: The Pragmatic Programmer's Guide is a good place to start. Although this freely available electronic edition can be a little dated, it is highly conceptual and covers basic syntax and the covered concepts and syntax are still highly relevant in Ruby.
Another resource for those new to Ruby is my article Accessorize Oracle Database with Ruby.
As is the case for most "Best Practices" books, this one is probably more attractive to those who are not completely new to Ruby. For the developer who is completely new to Ruby, the famous Programming Ruby: The Pragmatic Programmer's Guide is a good place to start. Although this freely available electronic edition can be a little dated, it is highly conceptual and covers basic syntax and the covered concepts and syntax are still highly relevant in Ruby.
Another resource for those new to Ruby is my article Accessorize Oracle Database with Ruby.
Tuesday, March 16, 2010
Changing the Default NetBeans License Template
In my previous blog post, I demonstrated how to remove the annoying template instruction comment added to all NetBeans-generated files. Peter Hull pointed out that one could also use this for a license as documented in Geertjan's Blog in the post Project-Level License Settings in NetBeans IDE 6.0. Although I generally don't need to include the license in the source code of software products I work on, this can be a useful feature for those that do.
The easiest way to apply one's own default template for licensing is to simply edit the default one that is used when you create a new NetBeans-generated source file. This is done by using the Template Manager which is accessed in NetBeans via the Tools->Templates menu. This is demonstrated by the next screen snapshot.
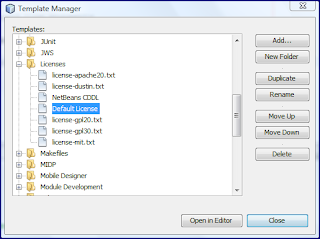
One can select the "Default License" and click on the "Open in Editor" button. When this is done, the initial text will include the comment that is all over the web about using of templates. However, the next screen snapshot demonstrates how I have changed its text.
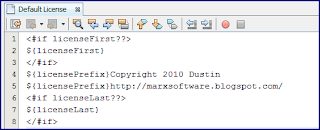
With this template in place, I can generate a new class or interface or other source code artifact to test it out. In this case, I generated a class via NetBeans's class generation wizard. The generated class, with my altered license information, is demonstrated in the next screen snapshot.
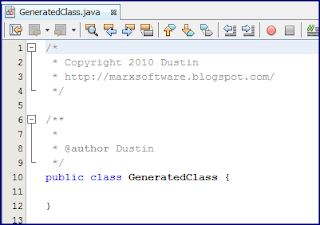
The above examples demonstrated changing the default comments included in each generated source file by changing the "Default License" template as opposed as to removing it altogether as I showed in my last blog post. Removing reference to the license altogether or changing the "Default License" are the easiest ways to deal with this.
As Geertjan's post demonstrates, NetBeans has supported the ability to add custom license as well. In the first screen snapshot in this post, there are other licenses already available (such as an Apache 2 license) and one can generate custom licenses. Doing this involves coordination between a property called
As would be expected, the
Caveat
As of this writing, I am having difficulty with custom licenses. When I set the property
There is one significant disadvantage to simply editing the "Default License": this will affect all new source files regardless of project. The advantage of specifying the license file via the
Conclusion
I generally prefer to simply turn off the auto-generated comments at the top of my source code files either by removing reference to them altogether or by editing the "Default License" to be empty. However, if one wants a custom comment, such as license information and/or contact information in the top of source files, NetBeans supports this through the license templates.
The easiest way to apply one's own default template for licensing is to simply edit the default one that is used when you create a new NetBeans-generated source file. This is done by using the Template Manager which is accessed in NetBeans via the Tools->Templates menu. This is demonstrated by the next screen snapshot.

One can select the "Default License" and click on the "Open in Editor" button. When this is done, the initial text will include the comment that is all over the web about using of templates. However, the next screen snapshot demonstrates how I have changed its text.

With this template in place, I can generate a new class or interface or other source code artifact to test it out. In this case, I generated a class via NetBeans's class generation wizard. The generated class, with my altered license information, is demonstrated in the next screen snapshot.

The above examples demonstrated changing the default comments included in each generated source file by changing the "Default License" template as opposed as to removing it altogether as I showed in my last blog post. Removing reference to the license altogether or changing the "Default License" are the easiest ways to deal with this.
As Geertjan's post demonstrates, NetBeans has supported the ability to add custom license as well. In the first screen snapshot in this post, there are other licenses already available (such as an Apache 2 license) and one can generate custom licenses. Doing this involves coordination between a property called
project.license in the nbproject/project.properties file and the reference to that file in the Templates Manager under the type of source file. For example, the Templates Manager entry for a "Java Class" contains this line:
<#include "../Licenses/license-${project.license}.txt">
As would be expected, the
${project.license} placeholder is replaced by the value that the property project.license is set to in the nbproject/project.properties file.Caveat
As of this writing, I am having difficulty with custom licenses. When I set the property
project.license=dustin and create a license template in the Template Manager named license-dustin.txt to match the format specified in the template for new Java class source code, the comment I get in a generated Java class file is "Error reading included file Templates/Classes/../Licenses/license-dustin.txt". I get this whether I try to select a file from the file system or "Duplicate" an existing license template and "Rename" it. Editing any of the pre-existing license templates provided with NetBeans 6.8 seems to work fine. This is the subject of a NetBeans Forum thread Topic 11600.There is one significant disadvantage to simply editing the "Default License": this will affect all new source files regardless of project. The advantage of specifying the license file via the
project.license property is that this is set on a per-project level. However, as I stated, I cannot get this to work properly at the moment.Conclusion
I generally prefer to simply turn off the auto-generated comments at the top of my source code files either by removing reference to them altogether or by editing the "Default License" to be empty. However, if one wants a custom comment, such as license information and/or contact information in the top of source files, NetBeans supports this through the license templates.
Sunday, March 14, 2010
Dealing with NetBeans New Source Template Annoyance
Yesterday I ran across one of those blog posts that made me realize that I am not the only one with a particular pet peeve. In this case, Emilian Bold addressed my pet peeve about developers leaving the NetBeans-generated template instruction comments in the code. In the blog post The Default NetBeans IDE Java Source Template is Polluting the Web, Emilian provides a Google query that illustrates that there are over 314 thousand (occurrences of the key string he provides). As a side note, it is interesting that 314 thousand is the number of occurrences on Pi Day.

The commented-out instructions that automatically appear in NetBeans-generated source code files looks like that shown in the next screen snapshot.

The text states:
I see these annoying comments checked into the source code of projects I have worked in which NetBeans has been a heavily used IDE, but I was surprised to see how many people have made source code available on the web with these comments still there. I dislike these so much that I will check a file out of the source code repository, remove these lines, and check the file back in. Emilian's post points out that I'm not the only one that finds these annoying (he calls them a pollutant, which I think is a good description for them).
Emilian points out that NetBeans includes this in source code automatically in an effort to help developers learn how to better use the IDE and customize it, but adds: "This might sound like a great idea in practice but it's broken since most people won't change it." It is my opinion that this is the crux of the problem for this case in particular and for this category of things in general (one of the people commenting on Emilian's blog points out that Eclipse has similar features). I don't mind so much that the IDE includes these comments, but I cannot understand why one would leave them in place when checking in the code. Emilian suggests some alternative approaches that might be preferable to including commented text in the generated classes, but I'd be happy just to see end user developers remove these lines as an easy fix.
NetBeans's generation of Java servlets provides more specific automatically generated comments to help the developer working on a new piece of code. The next screen snapshot shows a method called

Here is the generated code shown in the above screen snapshot.
I don't see many developers leaving the above generated code in place. This seems reasonable, but I wonder why this is different than the template instructions at the top of the source code which often do get left in place even as the code is checked into the source code repository.
Since getting serious about developing web applications with REST principles in mind, I often find myself not wanting NetBeans to automatically generate servlets that have the
The generated servlet code contains
It's been a Java servlet tradition for several years to have these methods do the same thing, but the rising popularity of REST has reminded us that the HTTP methods GET and POST are actually very different things despite what the web browser might tell you.
Fortunately, NetBeans makes it really easy to change these templates. How does one do that? That is where that comment that typically annoys me so much when left in managed source code actually comes in handy. That comment told me how to do it: "To change this template, choose Tools | Templates and open the template in the editor." I can change the template for the servlet under "Web" in the Tools->Templates wizard. There I can remove the commented out text and even change the behavior of
What if you wish to remove the comment about how to edit templates? That is done by changing the template of choice (such as the template for Java Class, Java Interface, or Java Servlet) and removing this line:
Once you save the template with this line removed, that text will no longer appear in files created based on that template.
The longer I develop software (and more specifically the longer that I refactor and maintain existing code), the more I realize that I want my code base to be lean. I loathe dead code and useless comments (as opposed to useful comments). It is nice to be able to work with the NetBeans template mechanism to remove some of these automatically inserted pieces of code before they even have a chance to get saved in the code repository.

The commented-out instructions that automatically appear in NetBeans-generated source code files looks like that shown in the next screen snapshot.

The text states:
/*
* To change this template, choose Tools | Templates
* and open the template in the editor.
*/
I see these annoying comments checked into the source code of projects I have worked in which NetBeans has been a heavily used IDE, but I was surprised to see how many people have made source code available on the web with these comments still there. I dislike these so much that I will check a file out of the source code repository, remove these lines, and check the file back in. Emilian's post points out that I'm not the only one that finds these annoying (he calls them a pollutant, which I think is a good description for them).
Emilian points out that NetBeans includes this in source code automatically in an effort to help developers learn how to better use the IDE and customize it, but adds: "This might sound like a great idea in practice but it's broken since most people won't change it." It is my opinion that this is the crux of the problem for this case in particular and for this category of things in general (one of the people commenting on Emilian's blog points out that Eclipse has similar features). I don't mind so much that the IDE includes these comments, but I cannot understand why one would leave them in place when checking in the code. Emilian suggests some alternative approaches that might be preferable to including commented text in the generated classes, but I'd be happy just to see end user developers remove these lines as an easy fix.
NetBeans's generation of Java servlets provides more specific automatically generated comments to help the developer working on a new piece of code. The next screen snapshot shows a method called
processRequest that has a simple example implementation provided in comments. This is shown in the next screen snapshot:
Here is the generated code shown in the above screen snapshot.
/**
* Processes requests for both HTTPGETandPOSTmethods.
* @param request servlet request
* @param response servlet response
* @throws ServletException if a servlet-specific error occurs
* @throws IOException if an I/O error occurs
*/
protected void processRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html;charset=UTF-8");
PrintWriter out = response.getWriter();
try {
/* TODO output your page here
out.println("<html>");
out.println("<head>");
out.println("<title>Servlet SomeServlet</title>");
out.println("</head>");
out.println("<body>");
out.println("<h1>Servlet SomeServlet at " + request.getContextPath () + "</h1>");
out.println("</body>");
out.println("</html>");
*/
} finally {
out.close();
}
}
I don't see many developers leaving the above generated code in place. This seems reasonable, but I wonder why this is different than the template instructions at the top of the source code which often do get left in place even as the code is checked into the source code repository.
Since getting serious about developing web applications with REST principles in mind, I often find myself not wanting NetBeans to automatically generate servlets that have the
@doPost and doGet methods automatically call a single method (processRequest in NetBeans 6.8 as shown above).The generated servlet code contains
doGet and doPost implementations as shown in the next code listing.
/**
* Handles the HTTPGETmethod.
* @param request servlet request
* @param response servlet response
* @throws ServletException if a servlet-specific error occurs
* @throws IOException if an I/O error occurs
*/
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
processRequest(request, response);
}
/**
* Handles the HTTPPOSTmethod.
* @param request servlet request
* @param response servlet response
* @throws ServletException if a servlet-specific error occurs
* @throws IOException if an I/O error occurs
*/
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
processRequest(request, response);
}
It's been a Java servlet tradition for several years to have these methods do the same thing, but the rising popularity of REST has reminded us that the HTTP methods GET and POST are actually very different things despite what the web browser might tell you.
Fortunately, NetBeans makes it really easy to change these templates. How does one do that? That is where that comment that typically annoys me so much when left in managed source code actually comes in handy. That comment told me how to do it: "To change this template, choose Tools | Templates and open the template in the editor." I can change the template for the servlet under "Web" in the Tools->Templates wizard. There I can remove the commented out text and even change the behavior of
doPost and doGet so that they don't call processRequest anymore (and I can remove processRequest altogether).What if you wish to remove the comment about how to edit templates? That is done by changing the template of choice (such as the template for Java Class, Java Interface, or Java Servlet) and removing this line:
<#include "../Licenses/license-${project.license}.txt">
Once you save the template with this line removed, that text will no longer appear in files created based on that template.
The longer I develop software (and more specifically the longer that I refactor and maintain existing code), the more I realize that I want my code base to be lean. I loathe dead code and useless comments (as opposed to useful comments). It is nice to be able to work with the NetBeans template mechanism to remove some of these automatically inserted pieces of code before they even have a chance to get saved in the code repository.
Monday, March 8, 2010
Oracle CHR Function
One of the presentations I enjoyed at Rocky Mountain Oracle Users Group (RMOUG) Training Days 2010 was Stephen Jackson's presentation "Using SQL to Generate SQL." I have used some of the techniques he discussed in his presentation to have SQL generate SQL, but one thing I had not thought of doing was to use the CHR function to make scripts more readable. Although this post focuses on using Oracle's CHR string function implementation, other databases support the CHR (or CHAR) function as well.
One example of the usefulness of CHR is in the creating of results that include characters that are significant in the query itself. Using CHR appropriately allows the SQL developer to avoid the need to escape these characters with query syntax significance. For example, to print the last names of employees in Oracle's HR sample schema with single quotes surrounding the last names, one could write a query like this:
The four single quotes successfully escape the quote mark both before and after the last name. Unfortunately, it can become easy to get lost in the quotes, especially for more complex queries. Because the ASCII decimal code of 39 produces a single quote when passed to CHR, the expression
For me, this is more readable. Similarly, even more difficult characters can be represented with the CHR function. For example, Stephen pointed out in his presentation that CHR(10) can be used to have a new line printed in the output.
One of the interesting ideas that Stephen discussed was use of a simple script to display the various character representations available via the CHR function. One can always reference a resource like Tech on the Net's ASCII Chart or asciitable.com, but it is interesting to simply display the representations via code:
The above snippet of code, when executed in SQL*Plus, will display a large number of the characters available in the basic and extended ASCII character set. One can use the spool command to spool the output to a file. On my Windows-based machine, I was even able to view these generated symbols in the spooled output file using the basic Notepad application.
Conclusion
As Stephen pointed out in his presentation, the CHR function can make SQL*Plus scripts more readable and maintainable.
One example of the usefulness of CHR is in the creating of results that include characters that are significant in the query itself. Using CHR appropriately allows the SQL developer to avoid the need to escape these characters with query syntax significance. For example, to print the last names of employees in Oracle's HR sample schema with single quotes surrounding the last names, one could write a query like this:
select '''' || last_name || '''' from employees;
The four single quotes successfully escape the quote mark both before and after the last name. Unfortunately, it can become easy to get lost in the quotes, especially for more complex queries. Because the ASCII decimal code of 39 produces a single quote when passed to CHR, the expression
CHR(39) can be used instead as shown next:
select CHR(39) || last_name || CHR(39) from employees;
For me, this is more readable. Similarly, even more difficult characters can be represented with the CHR function. For example, Stephen pointed out in his presentation that CHR(10) can be used to have a new line printed in the output.
One of the interesting ideas that Stephen discussed was use of a simple script to display the various character representations available via the CHR function. One can always reference a resource like Tech on the Net's ASCII Chart or asciitable.com, but it is interesting to simply display the representations via code:
-- displayCHR.sql
--
-- Display the characters associated with basic and extended ASCII codes.
--
SET head off
SET pagesize 0
SET linesize 120
SET trimspool on
SET feedback off
SET verify off
SET serveroutput on size 5000
BEGIN
FOR i IN 32..255 loop
Dbms_output.put_line(i || ' ' || chr(i));
END loop;
END;
/
The above snippet of code, when executed in SQL*Plus, will display a large number of the characters available in the basic and extended ASCII character set. One can use the spool command to spool the output to a file. On my Windows-based machine, I was even able to view these generated symbols in the spooled output file using the basic Notepad application.
Conclusion
As Stephen pointed out in his presentation, the CHR function can make SQL*Plus scripts more readable and maintainable.
Saturday, March 6, 2010
Correlation Between Typing Speed and Programming Competence
A colleague recently asked me, "Have you noticed that the better developers we've worked with are also fast typists?" I acknowledged that I had noticed relatively quick typing speed to be a common trait of most of the best developers that I know. It also made me think of the Jeff Atwood post We are Typists First, Programmers Second and the Steve Yegge post Programming's Dirty Little Secret.
I do know a few exceptions where a particularly talented developer is not even in the top half in terms of typing skills, but it is the rare exception. The majority of the best developers I've had the good fortune to work with are in the "top half" in terms of typing speed. I am a strong believer that good software development is much more than just hacking some code. So, I in this post, I look at the correlation between the ability to type rapidly and the likelihood of being a successful software developer.
It goes without saying that a fast typist is not necessarily a good developer. I've never seen (other than on television) anyone type faster than my mom. She had been an administrative assistant (called secretary at the time) for several years. This experience combined with an obvious knack for the skill had led to her typing 120+ words per minute with few or no mistakes (on typewriters no less). She was not a software developer.
Although it is true that typing is a big part of the software developer's job, so are many other things such as understanding customer needs, coming up with architectures and designs that feature the most important -ilities, working on teams, knowing language syntax, understanding various third-party products and frameworks, and so forth. Typing is clearly a big part of most software developers' daily routine, but what makes it seem to be so highly correlated with the most successful software developers?
We Do Well What We Do Often
In many ways, the correlation between typing and software development success is not so as much about faster typing leading to a better developer as it is about faster typing being evidence of countless hours spent with the keyboard writing code. In other words, it is not necessarily that faster typing makes the developer better or more efficient (though it obviously cannot hurt) as it is that the great developer is a fast typist simple because that developer has spent so much time coding (and learning to be a better typing as a pure side effect of those many hours). One could make the argument that becoming experienced and accomplished in software development makes one a better typist rather than making the argument that being a better typist makes one a better developer.
I have noticed that my fastest typing comes when I type the same thing over and over. What this means is that I end up being very quick to type things like build commands, database/SQL commands, application server administrative and deployment commands, configuration management commands, and the like. The things I do everyday are the things I do most quickly.
Efficient Typing Allows Time for Other Things
One advantage that faster typists have compared to developers with lesser typing skills is that less time spent typing in characters means more time doing the many other things that good software developers do: scripting routine tasks, writing and running tests, documenting for users and maintainers, learning new things, writing e-mail messages, writing blogs, etc. In an almost recursive fashion, many of these tasks that can have more time dedicated to them because a developer was able to type code more quickly are themselves beneficiaries of better typing skills as well.
Efficiency of Typing can Lead to Perceived Faster Typing
One of the interesting characteristics I've observed in many of the best developers I've worked with is their ability to take advantage of many different key strokes, macros, and other devices to accomplish the same task more quickly. Although just about every developer I work with these days uses an IDE, it wasn't all that long ago when certain developers could make the (truthful) argument that they could write and develop code more quickly in their simple text editor than most developers around them could with the IDE.
For the smallest of projects, I still find myself sometimes using these simple tools when the IDEs or other more advanced tools just feel unnecessarily heavy. I have amazed some people around me with my perceived vi prowess, but what they don't realize is that I'm really an amateur compared to some of the vi skills I have seen others possess. When these developers combine a powerful IDE with a vi emulator, it can be dizzying trying to watch them in action.
Some of the fastest developers I have worked with complement their own typing speed with knowledge of and familiarity with their favorite tools. This is often seen in the world of IDEs where a developer who knows the IDE well can take advantage of all types of different features to developer more quickly and accurately.
Fast Typing is an Inherent Advantage in Some Aspects of Software Development
Although it can be argued (as I did above) that fast typing is a side effect or consequence of years of inadvertently practicing typing while writing code, there is no question that some areas of software development are prone to benefit from faster typing. It is obvious that a fast typist has advantage when getting his or her thoughts into code, though I have seen that advantage at least partially mitigated by IDE code completion and other features.
Writing original code is an obvious area where faster typing is an advantage. Faster typing is also an advantage, however, for the person doing refactoring outside that supported well by the IDE. Faster typing might make a developer less concerned about having enough time to write that one last test he or she feels would be nice to have.
Typing is Not Writing
One of the areas where the correlation between fast typist and great developer breaks down most is when typing without creativity is considered. Developers' typing is more like authors' and reporters' typing and less like administrative assistants' typing and stenotyping. By this, I mean that a developer typically must insert his or her own creativity and thought into what he or she is typing. Rarely is the developer asked to simply type up some pseudocode or other previously dictated implementation. What this can mean is that the raw speed of typing may be not quite as important as it would be if typing up what someone else was saying or writing because some time is spent in that thinking.
Conclusion
It's not all that surprising that, at least in my experience, that the better developers generally tend to be faster typists. The correlation between productive developer and typing skills seems to enjoy somewhat of a causal relationship from both sides. Being a better developer as a result of years spent toiling over a keyboard writing code cannot help but make one more efficient with the keyboard. From the other perspective, faster typing skills help a developer to get more done in the same amount of time. As with just about everything in life and especially in software development, there are exceptions. I do know of some really good developers who are probably not in the top half of typist abilities, but they are the exception. Most of the best developers I know are also better than average typists. The good news is that developers can practice both at the same time. As one writes code, one also practices typing.
Additional References
⇒ Programming's Dirty Little Secret
⇒ We Are Typists First, Programmers Second
⇒ Speed Chess
⇒ Stack Overflow: Should Programmers Be Excellent Typists?
I do know a few exceptions where a particularly talented developer is not even in the top half in terms of typing skills, but it is the rare exception. The majority of the best developers I've had the good fortune to work with are in the "top half" in terms of typing speed. I am a strong believer that good software development is much more than just hacking some code. So, I in this post, I look at the correlation between the ability to type rapidly and the likelihood of being a successful software developer.
It goes without saying that a fast typist is not necessarily a good developer. I've never seen (other than on television) anyone type faster than my mom. She had been an administrative assistant (called secretary at the time) for several years. This experience combined with an obvious knack for the skill had led to her typing 120+ words per minute with few or no mistakes (on typewriters no less). She was not a software developer.
Although it is true that typing is a big part of the software developer's job, so are many other things such as understanding customer needs, coming up with architectures and designs that feature the most important -ilities, working on teams, knowing language syntax, understanding various third-party products and frameworks, and so forth. Typing is clearly a big part of most software developers' daily routine, but what makes it seem to be so highly correlated with the most successful software developers?
We Do Well What We Do Often
In many ways, the correlation between typing and software development success is not so as much about faster typing leading to a better developer as it is about faster typing being evidence of countless hours spent with the keyboard writing code. In other words, it is not necessarily that faster typing makes the developer better or more efficient (though it obviously cannot hurt) as it is that the great developer is a fast typist simple because that developer has spent so much time coding (and learning to be a better typing as a pure side effect of those many hours). One could make the argument that becoming experienced and accomplished in software development makes one a better typist rather than making the argument that being a better typist makes one a better developer.
I have noticed that my fastest typing comes when I type the same thing over and over. What this means is that I end up being very quick to type things like build commands, database/SQL commands, application server administrative and deployment commands, configuration management commands, and the like. The things I do everyday are the things I do most quickly.
Efficient Typing Allows Time for Other Things
One advantage that faster typists have compared to developers with lesser typing skills is that less time spent typing in characters means more time doing the many other things that good software developers do: scripting routine tasks, writing and running tests, documenting for users and maintainers, learning new things, writing e-mail messages, writing blogs, etc. In an almost recursive fashion, many of these tasks that can have more time dedicated to them because a developer was able to type code more quickly are themselves beneficiaries of better typing skills as well.
Efficiency of Typing can Lead to Perceived Faster Typing
One of the interesting characteristics I've observed in many of the best developers I've worked with is their ability to take advantage of many different key strokes, macros, and other devices to accomplish the same task more quickly. Although just about every developer I work with these days uses an IDE, it wasn't all that long ago when certain developers could make the (truthful) argument that they could write and develop code more quickly in their simple text editor than most developers around them could with the IDE.
For the smallest of projects, I still find myself sometimes using these simple tools when the IDEs or other more advanced tools just feel unnecessarily heavy. I have amazed some people around me with my perceived vi prowess, but what they don't realize is that I'm really an amateur compared to some of the vi skills I have seen others possess. When these developers combine a powerful IDE with a vi emulator, it can be dizzying trying to watch them in action.
Some of the fastest developers I have worked with complement their own typing speed with knowledge of and familiarity with their favorite tools. This is often seen in the world of IDEs where a developer who knows the IDE well can take advantage of all types of different features to developer more quickly and accurately.
Fast Typing is an Inherent Advantage in Some Aspects of Software Development
Although it can be argued (as I did above) that fast typing is a side effect or consequence of years of inadvertently practicing typing while writing code, there is no question that some areas of software development are prone to benefit from faster typing. It is obvious that a fast typist has advantage when getting his or her thoughts into code, though I have seen that advantage at least partially mitigated by IDE code completion and other features.
Writing original code is an obvious area where faster typing is an advantage. Faster typing is also an advantage, however, for the person doing refactoring outside that supported well by the IDE. Faster typing might make a developer less concerned about having enough time to write that one last test he or she feels would be nice to have.
Typing is Not Writing
One of the areas where the correlation between fast typist and great developer breaks down most is when typing without creativity is considered. Developers' typing is more like authors' and reporters' typing and less like administrative assistants' typing and stenotyping. By this, I mean that a developer typically must insert his or her own creativity and thought into what he or she is typing. Rarely is the developer asked to simply type up some pseudocode or other previously dictated implementation. What this can mean is that the raw speed of typing may be not quite as important as it would be if typing up what someone else was saying or writing because some time is spent in that thinking.
Conclusion
It's not all that surprising that, at least in my experience, that the better developers generally tend to be faster typists. The correlation between productive developer and typing skills seems to enjoy somewhat of a causal relationship from both sides. Being a better developer as a result of years spent toiling over a keyboard writing code cannot help but make one more efficient with the keyboard. From the other perspective, faster typing skills help a developer to get more done in the same amount of time. As with just about everything in life and especially in software development, there are exceptions. I do know of some really good developers who are probably not in the top half of typist abilities, but they are the exception. Most of the best developers I know are also better than average typists. The good news is that developers can practice both at the same time. As one writes code, one also practices typing.
Additional References
⇒ Programming's Dirty Little Secret
⇒ We Are Typists First, Programmers Second
⇒ Speed Chess
⇒ Stack Overflow: Should Programmers Be Excellent Typists?
Monday, March 1, 2010
Notes about Groovy's DataSet
I have blogged before about GroovySql and I find that it meets my needs nicely. However, some people prefer to use Groovy's DataSet class which the Groovy 1.7.1 API documentation describes as "an enhancement of Groovy's Sql class providing support for accessing and querying databases using POGO fields and operators rather than JDBC-level API calls and RDBMS column names."
Before getting to the DataSet example, I'll quickly demonstrate using GroovySql used to get the IT (department 60) employees from the HR sample schema in most Oracle databases.
The IT's department number is hard-coded into the query, but it works for this simple example and the output lists five employees in the IT department.
This same result can be achieved with the Groovy DataSet as shown next.
Comparing the second example (using DataSet) to the first example (using GroovySql directly) shows that the biggest difference is between using SQL/JDBC statements with GroovySql and using a more Java/Groovy-like syntax with the DataSet approach.
Now, let's replace the hard-coded 60 with an ID passed into the script as a command-line argument. Here is the version using GroovySql, followed by its output.

A first cut at using DataSet might look like this:
This doesn't work so well, as shown in the next screen snapshot:

The error message shown in the above screen snapshot states "Caught: groovy.lang.MissingPropertyException: No such property: sql for class: ..." In an effort to deal with this, I add static typing to the department ID variable as demonstrated in the next code listing.
Unfortunately, there is still an error as shown in the next screen snapshot.

The error is simply a result of not casting the String argument to an integer. The next code listing addresses that.
The output from trying to run this version is shown next. In this case, the error message states: "java.sql.SQLSyntaxErrorException: ORA-00936: missing expression." The departmentId variable is obviously not working in the closure.

One of the limitations of the Groovy DataSet is that constants (numbers and literal strings) must be used in construction of the narrowing clauses. I often need my SQL/JDBC statements to be dynamically populated and in such cases the GroovySql is the better choice. Although Groovy DataSet supports inserts in addition to queries (see its add method), the DataSet does not support updates or deletes.
There is one final disadvantage of DataSet that is fairly well advertised. Code using the DataSet must be included on the classpath whether it is a script or a class. Up until now, I've run the script from the same directory in which the script resides, so it was automatically on the classpath. The next screen snapshot indicates what happens when I run the script from a different directory.

The error states: "groovy.lang.GroovyRuntimeException: Could not find the ClassNode for MetaClass: org.codehaus.groovy.runtime.metaclass.ClosureMetaClass@1a0b53e[class getEmployeesViaDataSet$_run_closure1]". This error is documented in bug GROOVY-2450, bug GROOVY-1877, and in Groovy Goodness: Groovy SQL Dataset. Perhaps most obviously, even the API documentation for DataSet warns: "Currently, the Groovy source code for any accessed POGO must be on the classpath at runtime." The warning applies to code run as script or as a class.
The next screen snapshot demonstrates that including the directory in which the script presides directly on the classpath takes care of the previously encountered "Could not find ClassNode for MetaClass" error.

One of the interesting features of the DataSet is that it provides a getSql() method and a getParameters() method that make it easy to see the SQL statement underlying a DataSet along with the parameters it uses. Similarly the rows() method returns the result rows from a query.
Conclusion
Groovy's DataSet provides some nice advantages such as a more object friendly syntax for those who are SQL-adverse and providing easy access to the SQL that underlies it. However, the DataSet also has some disadvantages from the small nuisance of needing to include the code using DataSet on the classpath to more significant drawbacks of not being able to use it for updates/deletes and not being able to use dynamic values to narrow searches. I find GroovySql easy enough to use and appreciate its consistency in satisfying different needs. Therefore, I generally prefer GroovySql, but I also understand that others may find DataSet's advantages make it more attractive.
Before getting to the DataSet example, I'll quickly demonstrate using GroovySql used to get the IT (department 60) employees from the HR sample schema in most Oracle databases.
#!/usr/bin/env groovy
// Need to include the DataSource class on the classpath. Might look like this:
//
// groovy -cp C:\app\Dustin\product\11.1.0\db_1\jdbc\lib\ojdbc6.jar getEmployeesViaDataSet.groovy
import groovy.sql.Sql
sql = Sql.newInstance("jdbc:oracle:thin:@localhost:1521:orcl", "hr", "hr",
"oracle.jdbc.pool.OracleDataSource")
sql.eachRow("SELECT employee_id, last_name, first_name from employees where department_id = 60")
{
println "Employee of Department 200 is ${it.first_name} ${it.last_name}."
}
The IT's department number is hard-coded into the query, but it works for this simple example and the output lists five employees in the IT department.
Employee of Department 60 is Alexander Hunold.
Employee of Department 60 is Bruce Ernst.
Employee of Department 60 is David Austin.
Employee of Department 60 is Valli Pataballa.
Employee of Department 60 is Diana Lorentz.
This same result can be achieved with the Groovy DataSet as shown next.
#!/usr/bin/env groovy
// Need to include the DataSource class on the classpath. Might look like this:
//
// groovy -cp C:\app\Dustin\product\11.1.0\db_1\jdbc\lib\ojdbc6.jar getEmployeesViaDataSet.groovy
import groovy.sql.DataSet
import groovy.sql.Sql
sql = Sql.newInstance("jdbc:oracle:thin:@localhost:1521:orcl", "hr", "hr",
"oracle.jdbc.pool.OracleDataSource")
def employee = new DataSet(sql, 'EMPLOYEES')
def itEmployees = employee.findAll { it.department_id = 60 }
itEmployees.each{ println "Employee of Department 60 is ${it.first_name} ${it.last_name}" }
Comparing the second example (using DataSet) to the first example (using GroovySql directly) shows that the biggest difference is between using SQL/JDBC statements with GroovySql and using a more Java/Groovy-like syntax with the DataSet approach.
Now, let's replace the hard-coded 60 with an ID passed into the script as a command-line argument. Here is the version using GroovySql, followed by its output.
#!/usr/bin/env groovy
// Need to include the DataSource class on the classpath. Might look like this:
//
// groovy -cp C:\app\Dustin\product\11.1.0\db_1\jdbc\lib\ojdbc6.jar getEmployeesViaDataSet.groovy
if (!args) { println "Enter a Department ID!"; System.exit(-1); }
import groovy.sql.DataSet
import groovy.sql.Sql
departmentId = args[0]
sql = Sql.newInstance("jdbc:oracle:thin:@localhost:1521:orcl", "hr", "hr",
"oracle.jdbc.pool.OracleDataSource")
sql.eachRow("SELECT employee_id, last_name, first_name from employees where department_id = ${departmentId}")
{
println "Employee of Department ${departmentId} is ${it.first_name} ${it.last_name}."
}

A first cut at using DataSet might look like this:
#!/usr/bin/env groovy
// Need to include the DataSource class on the classpath. Might look like this:
//
// groovy -cp C:\app\Dustin\product\11.1.0\db_1\jdbc\lib\ojdbc6.jar getEmployeesViaDataSet.groovy
if (!args) {println "Enter a Department ID!"; System.exit(-1);}
import groovy.sql.DataSet
import groovy.sql.Sql
departmentId = args[0]
def employee = new DataSet(sql, 'EMPLOYEES')
def itEmployees = employee.findAll { it.department_id = departmentId }
itEmployees.each{ println "Employee of Department ${departmentId} is ${it.first_name} ${it.last_name}" }
This doesn't work so well, as shown in the next screen snapshot:

The error message shown in the above screen snapshot states "Caught: groovy.lang.MissingPropertyException: No such property: sql for class: ..." In an effort to deal with this, I add static typing to the department ID variable as demonstrated in the next code listing.
#!/usr/bin/env groovy
if (!args) {println "Enter a Department ID!"; System.exit(-1);}
// Need to include the DataSource class on the classpath. Might look like this:
//
// groovy -cp C:\app\Dustin\product\11.1.0\db_1\jdbc\lib\ojdbc6.jar getEmployeesViaDataSet.groovy
import groovy.sql.DataSet
import groovy.sql.Sql
int departmentId = args[0]
//sql = Sql.newInstance("jdbc:oracle:thin:@localhost:1521:orcl", "hr", "hr",
// "oracle.jdbc.pool.OracleDataSource")
//sql.eachRow("SELECT employee_id, last_name, first_name from employees where department_id = ${departmentId}")
//{
// println "Employee of Department ${departmentId} is ${it.first_name} ${it.last_name}."
//}
def employee = new DataSet(sql, 'EMPLOYEES')
def itEmployees = employee.findAll { it.department_id = departmentId }
itEmployees.each{ println "Employee of Department 60 is ${it.first_name} ${it.last_name}" }
Unfortunately, there is still an error as shown in the next screen snapshot.

The error is simply a result of not casting the String argument to an integer. The next code listing addresses that.
#!/usr/bin/env groovy
// Need to include the DataSource class on the classpath. Might look like this:
//
// groovy -cp C:\app\Dustin\product\11.1.0\db_1\jdbc\lib\ojdbc6.jar getEmployeesViaDataSet.groovy
if (!args) {println "Enter a Department ID!"; System.exit(-1);}
import groovy.sql.DataSet
import groovy.sql.Sql
int departmentId = args[0] as Integer
sql = Sql.newInstance("jdbc:oracle:thin:@localhost:1521:orcl", "hr", "hr",
"oracle.jdbc.pool.OracleDataSource")
def employee = new DataSet(sql, 'EMPLOYEES')
def itEmployees = employee.findAll { it.department_id = departmentId }
itEmployees.each{ println "Employee of Department ${departmentId} is ${it.first_name} ${it.last_name}" }
The output from trying to run this version is shown next. In this case, the error message states: "java.sql.SQLSyntaxErrorException: ORA-00936: missing expression." The departmentId variable is obviously not working in the closure.

One of the limitations of the Groovy DataSet is that constants (numbers and literal strings) must be used in construction of the narrowing clauses. I often need my SQL/JDBC statements to be dynamically populated and in such cases the GroovySql is the better choice. Although Groovy DataSet supports inserts in addition to queries (see its add method), the DataSet does not support updates or deletes.
There is one final disadvantage of DataSet that is fairly well advertised. Code using the DataSet must be included on the classpath whether it is a script or a class. Up until now, I've run the script from the same directory in which the script resides, so it was automatically on the classpath. The next screen snapshot indicates what happens when I run the script from a different directory.

The error states: "groovy.lang.GroovyRuntimeException: Could not find the ClassNode for MetaClass: org.codehaus.groovy.runtime.metaclass.ClosureMetaClass@1a0b53e[class getEmployeesViaDataSet$_run_closure1]". This error is documented in bug GROOVY-2450, bug GROOVY-1877, and in Groovy Goodness: Groovy SQL Dataset. Perhaps most obviously, even the API documentation for DataSet warns: "Currently, the Groovy source code for any accessed POGO must be on the classpath at runtime." The warning applies to code run as script or as a class.
The next screen snapshot demonstrates that including the directory in which the script presides directly on the classpath takes care of the previously encountered "Could not find ClassNode for MetaClass" error.

One of the interesting features of the DataSet is that it provides a getSql() method and a getParameters() method that make it easy to see the SQL statement underlying a DataSet along with the parameters it uses. Similarly the rows() method returns the result rows from a query.
Conclusion
Groovy's DataSet provides some nice advantages such as a more object friendly syntax for those who are SQL-adverse and providing easy access to the SQL that underlies it. However, the DataSet also has some disadvantages from the small nuisance of needing to include the code using DataSet on the classpath to more significant drawbacks of not being able to use it for updates/deletes and not being able to use dynamic values to narrow searches. I find GroovySql easy enough to use and appreciate its consistency in satisfying different needs. Therefore, I generally prefer GroovySql, but I also understand that others may find DataSet's advantages make it more attractive.
Subscribe to:
Comments (Atom)