One of the considerations when configuring Terracotta servers with tc-config.xml is the specification of health check properties between Terracotta servers (L2-L2), from clients to server (L1-L2), and from server to client (L2-L1). Terracotta checks the combination of these properties' configurations in high-availability scenarios to ensure that these combinations fall in certain ranges. This blog post demonstrates using Groovy to parse and analyze a given tc-config.xml file to determine whether Terracotta will provide a WARN-level message regarding these properties' configurations.
The "About HealthChecker" section of the Terracotta 4.3.2 BigMemory Max High-Availability Guide (PDF) describes the purpose of the HealthChecker: "HealthChecker is a connection monitor similar to TCP keep-alive. HealthChecker functions between Terracotta server instances (in High Availability environments), and between Terracotta sever instances and clients. Using HealthChecker, Terracotta nodes can determine if peer nodes are reachable, up, or in a GC operation. If a peer node is unreachable or down, a Terracotta node using HealthChecker can take corrective action."
The Terracotta 4.3.2 BigMemory Max High-Availability Guide includes a table under the section HealthChecker Properties that articulates the Terracotta properties that go into the calculations used to determine if warnings about misconfigured high availability should be logged. There are similarly named properties specified for each of the combinations (l2.healthcheck.l1.* properties for server-to-clients [L2L1], l2.healthcheck.l2.* for server-to-server [L2L2], and l1.healthcheck.l2.* for clients-to-server [L1L2]) and the properties significant to the high availability configuration checks (the * portion of the properties names just referenced) are ping.enabled, ping.idletime, ping.interval, ping.probes, socketConnect, socketConnectCount, and socketConnectTimeout. This post's associated Groovy script assumes that one has the ping.enabled and socketConnect properties for L2-L2, L1-L2, and L2-L1 all configured to true (which is the default for both properties for all L2L2, L1L2, L2L1 combinations).
The Terracotta class com.tc.l2.ha.HASettingsChecker detects two combinations of these properties that lead to WARN-level log messages starting with the phrase, "High Availability Not Configured Properly: ...". The two warning messages specifically state, "High Availability Not Configured Properly: L1L2HealthCheck should be less than L2-L2HealthCheck + ElectionTime + ClientReconnectWindow" and "High Availability Not Configured Properly: L1L2HealthCheck should be more than L2-L2HealthCheck + ElectionTime".
The Terracotta class HASettingsChecker implements the formula outlined in the "Calculating HealthChecker Maximum" section of the High Availability Guide in its method interNodeHealthCheckTime(int,int,int,int,int):
pingIdleTime + ((socketConnectCount) * (pingInterval * pingProbes + socketConnectTimeout *
pingInterval))
The following Groovy script parses an indicated tc-config.xml file and applies the same health check properties check to the relevant properties defined in that file's <tc-properties> section. The Groovy script shown here has no external dependencies other than a valid tc-config.xml file to be parsed and analyzed. The script would be shorter and require less future maintenance if it accessed the String constants defined in com.tc.properties.TCPropertiesConsts instead of defining its own hard-coded versions of these.
checkTCServerProperties.groovy
#!/usr/bin/env groovy
def cli = new CliBuilder(
usage: 'checkTCServerProperties -f <pathToTcConfigXmlFile> [-v] [-h]',
header: '\nAvailable options (use -h for help):\n',
footer: '\nParses referenced tc-config.xml file and analyzes its health check parameters..\n')
import org.apache.commons.cli.Option
cli.with
{
h(longOpt: 'help', 'Usage Information', required: false)
f(longOpt: 'file', 'Path to tc-config.xml File', args: 1, required: true)
v(longOpt: 'verbose', 'Specifies verbose output', args: 0, required: false)
}
def opt = cli.parse(args)
if (!opt) return
if (opt.h) cli.usage()
String tcConfigFileName = opt.f
boolean verbose = opt.v
println "Checking ${tcConfigFileName}'s properties..."
def tcConfigXml = new XmlSlurper().parse(tcConfigFileName)
TreeMap<String, String> properties = new TreeSet<>()
tcConfigXml."tc-properties".property.each
{ tcProperty ->
String tcPropertyName = tcProperty.@name
String tcPropertyValue = tcProperty.@value
properties.put(tcPropertyName, tcPropertyValue)
}
if (verbose)
{
properties.each
{ propertyName, propertyValue ->
println "${propertyName}: ${propertyValue}"
}
}
boolean isL2L1PingEnabled = extractBoolean(properties, "l2.healthcheck.l1.ping.enabled")
boolean isL2L2PingEnabled = extractBoolean(properties, "l2.healthcheck.l2.ping.enabled")
boolean isL1L2PingEnabled = extractBoolean(properties, "l1.healthcheck.l2.ping.enabled")
boolean isPingEnabled = isL2L1PingEnabled && isL2L2PingEnabled && isL1L2PingEnabled
println "Health Check Ping ${isPingEnabled ? 'IS' : 'is NOT'} enabled."
if (!isPingEnabled)
{
System.exit(-1)
}
Long pingIdleTimeL2L1 = extractLong(properties, "l2.healthcheck.l1.ping.idletime")
Long pingIdleTimeL2L2 = extractLong(properties, "l2.healthcheck.l2.ping.idletime")
Long pingIdleTimeL1L2 = extractLong(properties, "l1.healthcheck.l2.ping.idletime")
Long pingIntervalL2L1 = extractLong(properties, "l2.healthcheck.l1.ping.interval")
Long pingIntervalL2L2 = extractLong(properties, "l2.healthcheck.l2.ping.interval")
Long pingIntervalL1L2 = extractLong(properties, "l1.healthcheck.l2.ping.interval")
Long pingProbesL2L1 = extractLong(properties, "l2.healthcheck.l1.ping.probes")
Long pingProbesL2L2 = extractLong(properties, "l2.healthcheck.l2.ping.probes")
Long pingProbesL1L2 = extractLong(properties, "l1.healthcheck.l2.ping.probes")
boolean socketConnectL2L1 = extractBoolean(properties, "l2.healthcheck.l1.socketConnect")
boolean socketConnectL2L2 = extractBoolean(properties, "l2.healthcheck.l2.socketConnect")
boolean socketConnectL1L2 = extractBoolean(properties, "l1.healthcheck.l2.socketConnect")
if (!socketConnectL2L1 || !socketConnectL2L2 || !socketConnectL1L2)
{
println "Socket connect is disabled."
System.exit(-2)
}
Long socketConnectTimeoutL2L1 = extractLong(properties, "l2.healthcheck.l1.socketConnectTimeout")
Long socketConnectTimeoutL2L2 = extractLong(properties, "l2.healthcheck.l2.socketConnectTimeout")
Long socketConnectTimeoutL1L2 = extractLong(properties, "l1.healthcheck.l2.socketConnectTimeout")
Long socketConnectCountL2L1 = extractLong(properties, "l2.healthcheck.l1.socketConnectCount")
Long socketConnectCountL2L2 = extractLong(properties, "l2.healthcheck.l2.socketConnectCount")
Long socketConnectCountL1L2 = extractLong(properties, "l1.healthcheck.l2.socketConnectCount")
Long maximumL2L1 = calculateMaximumTime(pingIdleTimeL2L1, pingIntervalL2L1, pingProbesL2L1, socketConnectCountL2L1, socketConnectTimeoutL2L1)
Long maximumL2L2 = calculateMaximumTime(pingIdleTimeL2L2, pingIntervalL2L2, pingProbesL2L2, socketConnectCountL2L2, socketConnectTimeoutL2L2)
Long maximumL1L2 = calculateMaximumTime(pingIdleTimeL1L2, pingIntervalL1L2, pingProbesL1L2, socketConnectCountL1L2, socketConnectTimeoutL1L2)
if (verbose)
{
println "L2-L1 Maximum Time: ${maximumL2L1}"
println "L2-L2 Maximum Time: ${maximumL2L2}"
println "L1-L2 Maximum Time: ${maximumL1L2}"
}
long electionTime = 5000
long clientReconnectWindow = 120000
long maximumL2L2Election = maximumL2L2 + electionTime
long maximumL2L2ElectionReconnect = maximumL2L2Election + clientReconnectWindow
if (verbose)
{
println "L2-L2 Maximum Time + ElectionTime: ${maximumL2L2Election}"
println "L2-L2 Maximum Time + ElectionTime + Client Reconnect Window: ${maximumL2L2ElectionReconnect}"
}
if (maximumL1L2 < maximumL2L2Election)
{
print "WARNING: Will lead to 'High Availability Not Configured Properly: L1L2HealthCheck should be more than L2-L2HealthCheck + ElectionTime' "
println "because ${maximumL1L2} < ${maximumL2L2Election}."
}
else if (maximumL1L2 > maximumL2L2ElectionReconnect)
{
print "WARNING: Will lead to 'High Availability Not Configured Properly: L1L2HealthCheck should be less than L2-L2HealthCheck + ElectionTime + ClientReconnectWindow' "
println "because ${maximumL1L2} > ${maximumL2L2ElectionReconnect}."
}
/**
* Extract a Boolean value for the provided property name from the provided
* properties.
*
* @return Boolean value associated with the provided property name.
*/
boolean extractBoolean(TreeMap<String, String> properties, String propertyName)
{
return properties != null && properties.containsKey(propertyName)
? Boolean.valueOf(properties.get(propertyName))
: false
}
/**
* Extract a Long value for the provided property name from the provided
* properties.
*
* @return Long value associated with the provided property name.
*/
Long extractLong(TreeMap<String, String> properties, String propertyName)
{
return properties != null && properties.containsKey(propertyName)
? Long.valueOf(properties.get(propertyName))
: 0
}
/**
* Provides the maximum time as calculated using the following formula:
*
* Maximum Time =
* (ping.idletime) + socketConnectCount *
* [(ping.interval * ping.probes) + (socketConnectTimeout * ping.interval)]
*/
Long calculateMaximumTime(Long pingIdleTime, Long pingInterval, Long pingProbes,
Long socketConnectCount, Long socketConnectTimeout)
{
return pingIdleTime + socketConnectCount * pingInterval * (pingProbes + socketConnectTimeout)
}
This script will also be available on GitHub. At some point, I may address some of its weaknesses and limitations in that GitHub version. Specifically, as shown above, this script currently assumes the default values for "election time" and "client reconnect window", but these could be parsed from the tc-config.xml file.
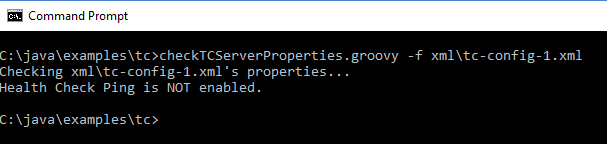
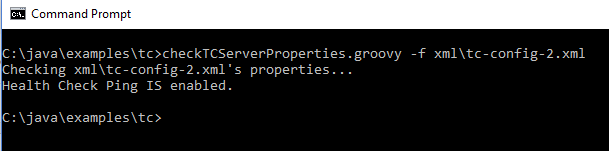
The following screen snapshots demonstrate this script in action against various tc-config.xml files. The first image depicts the script's behavior when ping is not enabled. The second image depicts the script's behavior when socket checking is not enabled. The third and fourth images depict the two warnings one might encounter when properties for high availability configuration are not configured properly. The fifth image depicts a fully successful execution of the script that indicates a configuration of health check properties that are in the expected ranges.
Ping Not Enabled (not default)
Socket Not Enabled (not default)

HealthCheck Properties Warning #1

HealthCheck Properties Warning #2

HealthCheck Properties Enabled and Configured Properly
I have used a simple spreadsheet to perform these calculations and that works fairly well. However, the Groovy script discussed in this post allows for automatic parsing of a candidate tc-config.xml file rather than needing to copy and paste values into the spreadsheet. The Groovy script could be adapted to use Terracotta provided Java files as discussed earlier. There are also several other enhancements that could make the script more useful such as parsing the client reconnect window and election time from the tc-config.xml file rather than assuming the default values.