It is important in many careers to be able to deal constructively with various forms of criticism. This is evidenced by all the posts and articles on the subject such as Are You Too Sensitive for Your Career, How to Accept Criticism While at Work, Ten Ideas How to Accept Criticism at Work, and Some Helpful Tips in Accepting Criticism. Although the skill of dealing with criticism effectively is useful for any career, it is particularly useful in software development. It is obvious that people working in industries such as retail, customer service, press, and entertainment must be able to deal with regular and sometimes heavy criticism. In this post I look at why the ability to effectively handle criticism can be just as important in software development as in any of these other industries. I only peripherally touch on what it means to "effectively handle criticism" because this is covered by numerous other articles and posts such as the ones previously referenced.
Code Reviews
I have long felt that writing source code is similar to writing prose. One of these similarities is that the author of code can feel a deep affection for what he or she writes that rivals what prose authors can feel about their work. This can make it difficult to hear others criticize that work. It is in many ways similar to an editor editing prose. In both cases, the author must be willing to listen to the criticism and, when the criticism is weighed and followed as appropriate, the product is better for it. The software developer, like the edited author, must be willing to hear that his or her work is not perfect and, hopefully in rare cases, may be severely flawed. For many software developers, this vehicle of criticism (the code review) is a regular part of the job.
Opinions and Subjectivity
Just as the prose editing process can be challenging due to the subjectivity involved in what makes for strong or interesting reading, much of what makes code "good" or even "beautiful" is in the eye of the beholder. It is sometimes even impossible to get two developers to agree on what is "simple" (see the excellent post Simplicity is Complicated). Because there is often more than one way to do something "correctly," the difference in options can become very subjective. This means that no matter how well a developer thinks he or she has done on a particular job, others can and will think that it could have been done better with their preferred approach. Software developers need to be confident, but this confidence can sometimes move into something else that leads to foisting opinions onto others. This is most readily seen in blog posts and even more so in feedback comments on blog posts. I typically dismiss "anonymous" comments or comments with no substance, but a fact-backed comment can be insightful, even if it disagrees with my thinking.
In general, we in the software development community are an opinionated bunch and we're not afraid to "share" those opinions with others even when they didn't ask for them.
Not Invented Here Syndrome
When talking about Not Invented Here (NIH) syndrome, the focus is often on how this leads to unnecessary new design, implementation, and testing of functionality that is already available and could be reused. However, another negative side of NIH can occur when the functionality is reimplemented before the original software's author has even "moved on" to something else. Often, NIH syndrome occurs in relation to third-party software or at least software written by other teams. When it is being reimplemented on the same team, this can become a form of criticism for the original author. There are implications that the original work was not good enough. Often, of course, this is not the case. There are many causes of NIH with only a small number of them being due to the original being truly insufficient for needs. Often, NIH is a result of a developer's desire to "write code" rather than "use code" or a developer's perception that it's easier to write something from scratch than to try and learn how to use something already in place. This can really get out of hand: I've seen pieces of functionality completely or almost completely re-written by each and every developer that touches that area of code. See In Defense of Not-Invented-Here-Syndrome for a discussion of situations in which NIH is not necessarily a bad thing.
Early Project/Product Termination
Most successful software developers that I know are enthusiastic about software and enjoy building things. They invest so much time, energy, and effort into their work that it often becomes extremely important to see it through to completion and deployment. Given this, it can be crushing when the project is terminated early or does not reach completion and delivery. It can be very difficult to feel motivated and to move onto another project or another product when the last one ends this way. This can be interpreted as criticism when the product or project is terminated prematurely, especially if the developer feels his or her work was part of the reason for it.
Delivered Product Reviews
Even when a software developer is fortunate enough to see their product go to market, the opportunity for receiving criticism is not past. In fact, it may only be beginning at this point. Customers can be fickle and can be demanding. Even products that start fast can quickly lose popularity. Reviews can be brutal, even when not deserved.
Blogs, Articles, Books, and Presentations
Software developers who write blogs, books, and articles and give presentations also open themselves up to potential (even likely) criticism that can be very public. This may be one explanation for why more developers don't do these things.
Conclusion
There are numerous opportunities for a software developer to be directly and indirectly criticized. There is significant room in software development for opinions and subjectivity and this makes it even easier for developers to be critical of each other, even when nothing wrong has been done. These can be constructive or destructive forms of criticism. I don't think anyone really likes to receive criticism, but developers who know how to handle it appropriately are more likely to be happy and successful.
Thursday, October 28, 2010
Saturday, October 23, 2010
Cannot Assume Serializability for Java Map's Nested Classes
A colleague of mine recently ran into an issue that I have not run into myself, but found to be interesting and, in my opinion, worth blogging about here. During some distributed Java development, my colleague observed that a NotSerializableException was encountered when he tried to pass the Set returned from Map's (HashMap in particular in this case) keySet() across the wire. Although I had never run into this myself, it is a commonly described issue online. Online references to this issue include Java HashMap.keySet return value, Bug Report 4501848, Bug Report 4756277, HashMap.Entry Not Serializable?, and Java Core APIs: private nonserializable classes in HashMap and Hashtable.
The following class demonstrates which
The above class runs through several popular
The output shown above leads to several interesting observations. First, and most importantly from this post's perspective, is the fact that most (all but
There are several approaches that can be used if the data from one of these classes nested within Map need to be distributed. The previously referenced bug reports provide an obvious "work around." One can copy the returned key set into its own new (and Serializable) Set:
The following class demonstrates which
Map implementations and which nested Map classes are Serializable and which are not for several popular standard Map implementations.package dustin.examples;
import java.io.Serializable;
import java.util.Collection;
import java.util.EnumMap;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
import java.util.WeakHashMap;
import java.util.concurrent.ConcurrentHashMap;
import static java.lang.System.out;
/**
* This class demonstrates that the nested classes for various types of Java
* maps are not Serializable.
*/
public class NonSerializableCollectionsInnerClassesDemonstrator
{
final String NEW_LINE = System.getProperty("line.separator");
/** Enum describing types of Maps used in this demonstration. */
private enum MapTypeEnum
{
CONCURRENT_HASH
{
public Map<Long, String> newSingleEntryMapInstance()
{
final Map<Long, String> map = new ConcurrentHashMap<Long, String>();
map.put(1L, "One");
return map;
}
},
HASH
{
public Map<Long, String> newSingleEntryMapInstance()
{
final Map<Long, String> map = new HashMap<Long, String>();
map.put(2L, "Two");
return map;
}
},
HASH_TABLE
{
public Map<Long, String> newSingleEntryMapInstance()
{
final Map<Long, String> map = new Hashtable<Long, String>();
map.put(3L, "Three");
return map;
}
},
LINKED_HASH
{
public Map<Long, String> newSingleEntryMapInstance()
{
final Map<Long, String> map = new LinkedHashMap<Long, String>();
map.put(4L, "Four");
return map;
}
},
TREE
{
public Map<Long, String> newSingleEntryMapInstance()
{
final Map<Long, String> map = new TreeMap<Long, String>();
map.put(5L, "Five");
return map;
}
},
WEAK_HASH
{
public Map<Long, String> newSingleEntryMapInstance()
{
final Map<Long, String> map = new WeakHashMap<Long, String>();
map.put(6L, "Six");
return map;
}
};
public abstract Map<Long, String> newSingleEntryMapInstance();
}
/**
* Indicate where the provided class defines a class that implements the
* java.io.Serializable interface.
*
* @param candidateClass Class whose serializable status is desired.
* @return {@code true} if the provided class is Serializable.
*/
public static boolean isSerializable(final Object candidateClass)
{
return candidateClass instanceof Serializable;
}
/**
* Print (to stdout) a simple message describing if the provided object
* is serializable or not.
*
* @param object Object whose class's status as Serializable or not is to be
* printed to stdout.
*/
public static void printSerializableStatus(final Object object)
{
final Class clazz = object.getClass();
out.println(
clazz.getName() + " is " + (isSerializable(object) ? "" : "NOT ") + "Serializable.");
}
/**
* Process a provided Map instance to indicate if the Map itself and its
* nested classes are Serializable.
*
* @param header Header to be printed before Serializable results are printed.
* @param map Map to be evaluated for Serializability or it and its nested classes.
*/
private void processSpecificMapInstance(
final String header, final Map<Long, String> map)
{
out.println(NEW_LINE + "===== " + header + " =====");
printSerializableStatus(map);
final Set<Long> mapKeySet = map.keySet();
printSerializableStatus(mapKeySet);
final Iterator<Long> mapKeySetIterator = mapKeySet.iterator();
printSerializableStatus(mapKeySetIterator);
final Collection<String> mapValues = map.values();
printSerializableStatus(mapValues);
for (final Map.Entry<Long, String> mapEntrySet : map.entrySet())
{
printSerializableStatus(mapEntrySet);
}
}
/**
* Method for explicitly creating EnumMap to check it and its nested classes
* for Serializability.
*/
private void processAndDemonstrateEnumMap()
{
out.println(NEW_LINE + "===== ENUMMAP =====");
final Map<MapTypeEnum, String> map = new EnumMap(MapTypeEnum.class);
map.put(MapTypeEnum.HASH, "HashMap");
printSerializableStatus(map);
final Set<MapTypeEnum> mapKeySet = map.keySet();
printSerializableStatus(mapKeySet);
final Iterator<MapTypeEnum> mapKeySetIterator = mapKeySet.iterator();
printSerializableStatus(mapKeySetIterator);
final Collection<String> mapValues = map.values();
printSerializableStatus(mapValues);
for (final Map.Entry<MapTypeEnum, String> mapEntrySet : map.entrySet())
{
printSerializableStatus(mapEntrySet);
}
}
/**
* Demonstrate Serializability status of different Map implementations and
* the Serializability of those Map instance's nested classes.
*/
private void demonstrateMapNestedClassesSerializability()
{
final Map<Long, String> hashMap = MapTypeEnum.HASH.newSingleEntryMapInstance();
processSpecificMapInstance("HASHMAP", hashMap);
final Map<Long, String> linkedHashMap = MapTypeEnum.LINKED_HASH.newSingleEntryMapInstance();
processSpecificMapInstance("LINKEDHASHMAP", linkedHashMap);
final Map<Long, String> concurrentHashMap = MapTypeEnum.CONCURRENT_HASH.newSingleEntryMapInstance();
processSpecificMapInstance("CONCURRENTHASHMAP", concurrentHashMap);
final Map<Long, String> weakHashMap = MapTypeEnum.WEAK_HASH.newSingleEntryMapInstance();
processSpecificMapInstance("WEAKHASHMAP", weakHashMap);
final Map<Long, String> treeMap = MapTypeEnum.TREE.newSingleEntryMapInstance();
processSpecificMapInstance("TREEMAP", treeMap);
final Map<Long, String> hashTable = MapTypeEnum.HASH_TABLE.newSingleEntryMapInstance();
processSpecificMapInstance("HASHTABLE", hashTable);
processAndDemonstrateEnumMap();
}
/**
* Main executable function to run the demonstrations.
*
* @param arguments Command-line arguments; none expected.
*/
public static void main(final String[] arguments)
{
final NonSerializableCollectionsInnerClassesDemonstrator instance =
new NonSerializableCollectionsInnerClassesDemonstrator();
instance.demonstrateMapNestedClassesSerializability();
}
}
The above class runs through several popular
Map implementations (EnumMap, HashMap, LinkedHashMap, TreeMap, Hashtable, WeakHashMap, ConcurrentHashMap) and prints out whether each Map implementation and its nested classes are Serializable. The output it generates is shown next.===== HASHMAP ===== java.util.HashMap is Serializable. java.util.HashMap$KeySet is NOT Serializable. java.util.HashMap$KeyIterator is NOT Serializable. java.util.HashMap$Values is NOT Serializable. java.util.HashMap$Entry is NOT Serializable. ===== LINKEDHASHMAP ===== java.util.LinkedHashMap is Serializable. java.util.HashMap$KeySet is NOT Serializable. java.util.LinkedHashMap$KeyIterator is NOT Serializable. java.util.HashMap$Values is NOT Serializable. java.util.LinkedHashMap$Entry is NOT Serializable. ===== CONCURRENTHASHMAP ===== java.util.concurrent.ConcurrentHashMap is Serializable. java.util.concurrent.ConcurrentHashMap$KeySet is NOT Serializable. java.util.concurrent.ConcurrentHashMap$KeyIterator is NOT Serializable. java.util.concurrent.ConcurrentHashMap$Values is NOT Serializable. java.util.concurrent.ConcurrentHashMap$WriteThroughEntry is Serializable. ===== WEAKHASHMAP ===== java.util.WeakHashMap is NOT Serializable. java.util.WeakHashMap$KeySet is NOT Serializable. java.util.WeakHashMap$KeyIterator is NOT Serializable. java.util.WeakHashMap$Values is NOT Serializable. java.util.WeakHashMap$Entry is NOT Serializable. ===== TREEMAP ===== java.util.TreeMap is Serializable. java.util.TreeMap$KeySet is NOT Serializable. java.util.TreeMap$KeyIterator is NOT Serializable. java.util.TreeMap$Values is NOT Serializable. java.util.TreeMap$Entry is NOT Serializable. ===== HASHTABLE ===== java.util.Hashtable is Serializable. java.util.Collections$SynchronizedSet is Serializable. java.util.Hashtable$Enumerator is NOT Serializable. java.util.Collections$SynchronizedCollection is Serializable. java.util.Hashtable$Entry is NOT Serializable. ===== ENUMMAP ===== java.util.EnumMap is Serializable. java.util.EnumMap$KeySet is NOT Serializable. java.util.EnumMap$KeyIterator is NOT Serializable. java.util.EnumMap$Values is NOT Serializable. java.util.EnumMap$EntryIterator is NOT Serializable.
The output shown above leads to several interesting observations. First, and most importantly from this post's perspective, is the fact that most (all but
WeakHashMap) of the Map implementations are themselves Serializable, but most of them (all but Hashtable) have nested classes (for keyset, values, and entryset) that are NOT Serializable.There are several approaches that can be used if the data from one of these classes nested within Map need to be distributed. The previously referenced bug reports provide an obvious "work around." One can copy the returned key set into its own new (and Serializable) Set:
Copy the values of the Set returned byThis blog post has attempted to demonstrate thatkeySet(),entrySet()orvalues()into a newHashSetorTreeSetobject:Set obj = new HashSet(myMap.keySet());
Serializable cannot be taken for granted. This is particularly true when dealing with nested classes in Map implementations.
Friday, October 22, 2010
Ten Tips for Using Java Stack Traces
Most Java developers are somewhat familiar with Java stack traces and how to read and analyze stack traces. However, for beginning Java developers, there are some areas of stack traces that might be a little confusing. In this post, I look at some tips for reading Java stack traces and responding appropriately based on what the stack trace reports.
1. Stack Traces Are Not Just for Errors and Exceptions
A common misconception among new Java developers and among people not familiar with Java is that stack traces indicate thrown exceptions. While stack traces are commonly associated with encountered exceptions, a Java developer can access a stack's trace at any time with no exception required. One way to do this is to call Thread.currentThread().getStackTrace() to access an array of StackTraceElements. I demonstrated this previously in my post The Surprisingly Simple StackTraceElement. It can be useful to access a stack trace even outside of an exceptional situation to understand how code flows. The
Another non-error stack trace usage is related to Java's ability to provide details about a running process when prompted from the command-line. This is described in more detail in a later section of this post.
2. Stack Trace is Presented from Latest to Earliest
One of the most important concepts of correctly understanding a stack trace is to recognize that it lists the execution path in reverse chronological order from most recent operation to earliest operation. In many ways, analyzing a stack trace correctly is like analyzing compiler errors correctly: order matters. With the compiler errors, it is generally best to analyze the first compiler error because that often causes subsequent compiler errors. Similarly, with a stack trace, it's often most useful to start with the most recent operation and work backwards as necessary up the stack trace to see how that condition was reached. For some exceptions, like some NullPointerExceptions, analysis of the line on which the exception occurred can be all that is needed to understand what went wrong.
3. Understand Chained Exceptions
Another important observation is that stack traces that do indicate exceptions often include chained exceptions. This is important to understand because it is often the case that one of the fundamental exceptions underlying the last encountered exception is the real culprit that must be appropriately addressed. Just as addressing the last compiler error reported before addressing the first reported error rarely is a good idea, it is similarly important to analyze the underlying exception. This chained exception facility was a welcome addition to Java 1.4 because it has allowed Java developers to more easily determine the real underlying cause of various exceptions. Often the most important exception to pay attention to in a long list of chained exceptions is the first one that occurred (typically listed at the very bottom of a lengthy stack trace and often preceded by "Caused by" notation).
4. Compile with Debug Turned On
When stack traces are being used to determine why an exception occurred or what the code flow was, it can be very useful to have access to the line numbers of each executed step covered by the stack trace. By default in Oracle's Java SE 6 javac, line numbers and source file names are included in stack traces. It is easy to make disable the printing of this information by setting javac's
5. Logging and Handling Exception Stack Traces
Because Java stack traces are so often associated with exceptions, it is useful to know how to report these properly. Fortunately, two of the most popular Java logging frameworks, java.util.logging and log4j, provide convenient methods for logging exceptions that will handle the stack trace information automatically. For example,
It is sometimes necessary or at least useful to access a stack trace in code situations other than logging. One way of doing this is to use the Throwable.getStackTrace() that returns an array of StackTraceElements. Another approach is to use one of the overloaded versions of Throwable.getStackTrace() that do not simply print the stack trace to standard error. These two overloaded methods allow access to the exception's stack trace via either a PrintStream or a PrintWriter. The next two code snippets demonstrate extracting a String from a
Extracting String from Throwable Via PrintWriter
Extracting String from Throwable Via PrintStream
6. Multiple Approaches for Generating/Accessing Stack Traces
Java supports several approaches for accessing stack traces. Several of these are outlined in An Introduction to Java Stack Traces and I've covered a couple here already. As described in Tip #1, the stack trace of the current execution can be retrieved from the current thread. The immediately preceding tip, Tip #5, covered extracting of a stack trace from an exception/error (Throwable).
There are times when it is useful to see what the current thread and other threads are doing. Java supports this by accepting a signal and responding by displaying pertinent details. Signal handling can be a little different across platforms, so it is worth learning how to send signals from the platforms used for one's Java applications. The Sun/Oracle java launcher documentation provides significant details about its JVM signal handling in the section that describes the -Xrs option (-X indicates non-standard option). Besides explaining how to use
Assuming that the

For Linux and Unix systems, this same signal is sent differently. It can be sent with CTRL-\ (CTRL button followed by back slash) or with the command
Java IDEs such as Eclipse and NetBeans also provide mechanisms for seeing current thread dumps and stack traces.
7. Understand Java Class/Interface Naming Conventions
When reading and analyzing a Java stack trace, it is helpful to understand the class and interface naming conventions. One source of information on these conventions is provided in the Javadoc documentation for Class.getName(). This documentation explains the naming conventions for classes, interfaces, arrays, primitives, and so forth. It states that arrays are denoted with square brace:
The naming conventions in stack traces can be dependent on the JVM implementation, so it's worthwhile to learn what the naming conventions are for the particular JVM being used.
8. Be Cognizant of Synthetic and Bridge Methods
In many stack traces, it is fairly obvious which methods are being successively invoked by tracing through the stack trace. Sometimes, however, there can be unrecognized methods. These might be from injected aspects or might be compiler-generated methods such as synthetic and bridge methods. I discussed synthetic methods in greater detail in my blog post Java's Synthetic Methods. As I stated in that post, synthetic methods are created by the compiler and usually have, in Sun's/Oracle's JVM, names such as
9. Dude, Where's My Stack Trace?
Stack traces can be extremely useful in debugging and understanding how an application works, but they are obviously less than effective if not readily available. As described above, some Java products (such as the logging frameworks) make logging of stack traces easier. Other products log stack traces or write out their own stack traces to product-specific directories or logs. Therefore, it's important when using a new framework, tool, library, or IDE to learn where it writes its logs and stack traces. This tip also covers other essential steps such as configuring loggers appropriately to write to the appropriate locations.
10. Magnify the Power of Stack Traces with Tooling
The majority of this post has focused on reading and manually analyzing stack traces. Tools are now available that can make use of stack traces and make use of stack traces much more efficient. Eclipse's Stacktrace Console is a good example of what a Java IDE can do to make use of stack traces easier. Stack traces can be pasted into this tool and then portions of the stack trace can be clicked on to be taken directly to that class and method. NetBeans offers similar tooling features that support easier access of stack traces to the underlying classes and methods displayed in the stack trace. Likewise, these IDEs also support generating/displaying thread dumps.
There are numerous other useful tools available in the Java ecosystem for more efficient use of Java stack traces and dumps. These include VisualVM (see my post Thread Analysis with VisualVM), jstack, and adaptj's StackTrace.
Another "tool" that is useful in conjunction with thread analysis is the powerful search engine. Although I agree that there is merit to not going right to the search engine for every problem, I have also been the beneficiary more times than I can recall of others' insight and experiences in resolving especially difficult problems. This is why I have written before that more software developers should write blogs. Search engines make it much easier to find a description of a potential fix to some nasty problems. It is often the stack trace that provides the best clues for finding the appropriate matches via search engines such as Google, Yahoo!, and Bing. Stack trace excerpts are often found in forum threads and blog posts that either directly address the issue or provide enough information to help think through what related condition might be causing the issue.
Conclusion
The humble stack trace is one of the Java developer's most powerful tools. It is especially powerful in debugging and analyzing existing software, but can even be useful in software development. In this post I have attempted to outline some simple techniques for getting the most value from these stack traces.
1. Stack Traces Are Not Just for Errors and Exceptions
A common misconception among new Java developers and among people not familiar with Java is that stack traces indicate thrown exceptions. While stack traces are commonly associated with encountered exceptions, a Java developer can access a stack's trace at any time with no exception required. One way to do this is to call Thread.currentThread().getStackTrace() to access an array of StackTraceElements. I demonstrated this previously in my post The Surprisingly Simple StackTraceElement. It can be useful to access a stack trace even outside of an exceptional situation to understand how code flows. The
StackTraceElement is also useful because it allows for granular access to pieces of the stack trace.Another non-error stack trace usage is related to Java's ability to provide details about a running process when prompted from the command-line. This is described in more detail in a later section of this post.
2. Stack Trace is Presented from Latest to Earliest
One of the most important concepts of correctly understanding a stack trace is to recognize that it lists the execution path in reverse chronological order from most recent operation to earliest operation. In many ways, analyzing a stack trace correctly is like analyzing compiler errors correctly: order matters. With the compiler errors, it is generally best to analyze the first compiler error because that often causes subsequent compiler errors. Similarly, with a stack trace, it's often most useful to start with the most recent operation and work backwards as necessary up the stack trace to see how that condition was reached. For some exceptions, like some NullPointerExceptions, analysis of the line on which the exception occurred can be all that is needed to understand what went wrong.
3. Understand Chained Exceptions
Another important observation is that stack traces that do indicate exceptions often include chained exceptions. This is important to understand because it is often the case that one of the fundamental exceptions underlying the last encountered exception is the real culprit that must be appropriately addressed. Just as addressing the last compiler error reported before addressing the first reported error rarely is a good idea, it is similarly important to analyze the underlying exception. This chained exception facility was a welcome addition to Java 1.4 because it has allowed Java developers to more easily determine the real underlying cause of various exceptions. Often the most important exception to pay attention to in a long list of chained exceptions is the first one that occurred (typically listed at the very bottom of a lengthy stack trace and often preceded by "Caused by" notation).
4. Compile with Debug Turned On
When stack traces are being used to determine why an exception occurred or what the code flow was, it can be very useful to have access to the line numbers of each executed step covered by the stack trace. By default in Oracle's Java SE 6 javac, line numbers and source file names are included in stack traces. It is easy to make disable the printing of this information by setting javac's
-g:none option, but this is not typically a good idea during development. Most build tools also make it easy to turn on debugging and control the debugging level. Ant, for example, provides the debug attribute for the javac task that can be set to true to turn debugging on.5. Logging and Handling Exception Stack Traces
Because Java stack traces are so often associated with exceptions, it is useful to know how to report these properly. Fortunately, two of the most popular Java logging frameworks, java.util.logging and log4j, provide convenient methods for logging exceptions that will handle the stack trace information automatically. For example,
java.util.logging provides an overloaded version of Logger.log that accepts a Throwable and log4j provides several overloaded methods on its Logger class that allow Throwables to be logged with a normal log message.It is sometimes necessary or at least useful to access a stack trace in code situations other than logging. One way of doing this is to use the Throwable.getStackTrace() that returns an array of StackTraceElements. Another approach is to use one of the overloaded versions of Throwable.getStackTrace() that do not simply print the stack trace to standard error. These two overloaded methods allow access to the exception's stack trace via either a PrintStream or a PrintWriter. The next two code snippets demonstrate extracting a String from a
Throwable using PrintWriter and PrintStream respectively.Extracting String from Throwable Via PrintWriter
/**
* Provides a String representation of the provided Throwable's stack trace
* that is extracted via PrintWriter.
*
* @param throwable Throwable/Exception from which stack trace is to be
* extracted.
* @return String with provided Throwable's stack trace.
*/
public static String accessExceptionStackTraceViaPrintWriter(final Throwable throwable)
{
final Writer writer = new StringWriter();
final PrintWriter printWriter = new PrintWriter(writer);
throwable.printStackTrace(printWriter);
return writer.toString();
}
Extracting String from Throwable Via PrintStream
/**
* Provides a String representation of the provided Throwable's stack trace
* that is extracted via PrintStream.
*
* @param throwable Throwable/Exception from which stack trace is to be
* extracted.
* @return String with provided Throwable's stack trace.
*/
public static String accessExceptionStackTraceViaPrintStream(final Throwable throwable)
{
final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final PrintStream printStream = new PrintStream(baos);
throwable.printStackTrace(printStream);
String exceptionStr = "";
try
{
exceptionStr = baos.toString("UTF-8");
}
catch(Exception ex)
{
exceptionStr = "Unavailable";
}
return exceptionStr;
}
6. Multiple Approaches for Generating/Accessing Stack Traces
Java supports several approaches for accessing stack traces. Several of these are outlined in An Introduction to Java Stack Traces and I've covered a couple here already. As described in Tip #1, the stack trace of the current execution can be retrieved from the current thread. The immediately preceding tip, Tip #5, covered extracting of a stack trace from an exception/error (Throwable).
There are times when it is useful to see what the current thread and other threads are doing. Java supports this by accepting a signal and responding by displaying pertinent details. Signal handling can be a little different across platforms, so it is worth learning how to send signals from the platforms used for one's Java applications. The Sun/Oracle java launcher documentation provides significant details about its JVM signal handling in the section that describes the -Xrs option (-X indicates non-standard option). Besides explaining how to use
-Xrs to turn off the JVM responding to received signals, this documentation also provides more details regarding the JVM handling of the signals SIGQUIT, SIGHUP, SIGINT, and SIGTERM.Assuming that the
-Xrs option is not used, using CTRL-BREAK in the Windows console window from which a Java application started leads to a thread dump of the current threads being displayed. This is demonstrated in the following screen snapshot of running a Java application and seeing the thread dump in Windows PowerShell.
For Linux and Unix systems, this same signal is sent differently. It can be sent with CTRL-\ (CTRL button followed by back slash) or with the command
kill -QUIT pid (where 'pid' is the process ID). The jstack utility tool is also easily used to see the threads associated with a particular process (often for specified process identifier).Java IDEs such as Eclipse and NetBeans also provide mechanisms for seeing current thread dumps and stack traces.
7. Understand Java Class/Interface Naming Conventions
When reading and analyzing a Java stack trace, it is helpful to understand the class and interface naming conventions. One source of information on these conventions is provided in the Javadoc documentation for Class.getName(). This documentation explains the naming conventions for classes, interfaces, arrays, primitives, and so forth. It states that arrays are denoted with square brace:
[. It also explains that array elements are marked with various letters depending on their types: L for classes and interfaces, Z for boolean, B for byte, C for char, D for double, F for float, I for int, J for long, and S for short. Knowing what these letters represent in array representations can make it easier to read information regarding these within stack traces. As I discussed in the blog post Heap Dump and Analysis with VisualVM, these same naming conventions are also described in the JVM specification for .class file format.The naming conventions in stack traces can be dependent on the JVM implementation, so it's worthwhile to learn what the naming conventions are for the particular JVM being used.
8. Be Cognizant of Synthetic and Bridge Methods
In many stack traces, it is fairly obvious which methods are being successively invoked by tracing through the stack trace. Sometimes, however, there can be unrecognized methods. These might be from injected aspects or might be compiler-generated methods such as synthetic and bridge methods. I discussed synthetic methods in greater detail in my blog post Java's Synthetic Methods. As I stated in that post, synthetic methods are created by the compiler and usually have, in Sun's/Oracle's JVM, names such as
access$100 and access$200.9. Dude, Where's My Stack Trace?
Stack traces can be extremely useful in debugging and understanding how an application works, but they are obviously less than effective if not readily available. As described above, some Java products (such as the logging frameworks) make logging of stack traces easier. Other products log stack traces or write out their own stack traces to product-specific directories or logs. Therefore, it's important when using a new framework, tool, library, or IDE to learn where it writes its logs and stack traces. This tip also covers other essential steps such as configuring loggers appropriately to write to the appropriate locations.
10. Magnify the Power of Stack Traces with Tooling
The majority of this post has focused on reading and manually analyzing stack traces. Tools are now available that can make use of stack traces and make use of stack traces much more efficient. Eclipse's Stacktrace Console is a good example of what a Java IDE can do to make use of stack traces easier. Stack traces can be pasted into this tool and then portions of the stack trace can be clicked on to be taken directly to that class and method. NetBeans offers similar tooling features that support easier access of stack traces to the underlying classes and methods displayed in the stack trace. Likewise, these IDEs also support generating/displaying thread dumps.
There are numerous other useful tools available in the Java ecosystem for more efficient use of Java stack traces and dumps. These include VisualVM (see my post Thread Analysis with VisualVM), jstack, and adaptj's StackTrace.
Another "tool" that is useful in conjunction with thread analysis is the powerful search engine. Although I agree that there is merit to not going right to the search engine for every problem, I have also been the beneficiary more times than I can recall of others' insight and experiences in resolving especially difficult problems. This is why I have written before that more software developers should write blogs. Search engines make it much easier to find a description of a potential fix to some nasty problems. It is often the stack trace that provides the best clues for finding the appropriate matches via search engines such as Google, Yahoo!, and Bing. Stack trace excerpts are often found in forum threads and blog posts that either directly address the issue or provide enough information to help think through what related condition might be causing the issue.
Conclusion
The humble stack trace is one of the Java developer's most powerful tools. It is especially powerful in debugging and analyzing existing software, but can even be useful in software development. In this post I have attempted to outline some simple techniques for getting the most value from these stack traces.
Monday, October 18, 2010
Java's Synthetic Methods
In this blog post, I look at the concept of Java synthetic methods. The post summarizes what a Java synthetic method is, how one can be created and identified, and the implications of Java synthetic methods on Java development.
The Java Language Specification (section 13.1) states "Any constructs introduced by the compiler that do not have a corresponding construct in the source code must be marked as synthetic, except for default constructors and the class initialization method." Further clues as to the meaning of synthetic in Java can be found in the Javadoc documentation for Member.isSynthetic(). That method's documentation states that it returns "true if and only if this member was introduced by the compiler." I like that very short definition of "synthetic": a Java construct introduced by the compiler.
The Java compiler must create synthetic methods on nested classes when their attributes specified with the private modifier are accessed by the enclosing class. The next code sample indicates this situation.
DemonstrateSyntheticMethods.java (Enclosing Class Invokes One Nested Class Private Attribute)
The above code compiles without incident. When javap is run against the compiled
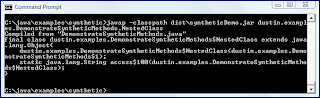
As the above screen snapshot indicates, a synthetic method with the name
DemonstrateSyntheticMethods.java (Enclosing Class Invokes Four Nested Class Private Attributes)
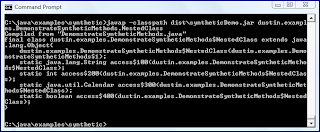
As the previous two code snippets above and the associated images show, the Java compiler introduces synthetic methods on an as-needed basis. When only one of the nested class's private attributes was accessed by the enclosing class, only one synthetic method (
In all cases of an enclosing class accessing its nested class's private data, a synthetic method was created to allow that access to happen. What happens when the nested class provides an accessor for its private data that the enclosing class can use? That is demonstrated in the next code listing and in its output as shown in the next screen snapshot.
DemonstrateSyntheticMethods.java with Nested Class Public Accessor for Private Data

The above screen snapshot demonstrates that the compiler did not need to generate a synthetic method for accessing the private Date attribute in the nested class because the enclosing class accessed that attribute via the provided
The last screen snapshot brings up another observation. As the newly added
The Java reflection APIs provide another approach for determining synthetic methods. The next code listing is for a Groovy script that will use the Java reflection APIs to conveniently provide details regarding the methods of the nested class shown above.
reflectOnMethods.groovy
When the above Groovy script is executed against the class and nested class shown above, the output is that shown in the next screen snapshot.
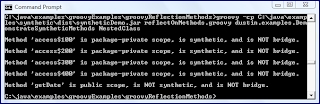
The results of the Groovy script shown in the previous image verify what javap had already told us: there are four synthetic methods and one non-synthetic method defined on the nested class
The addition of synthetic methods to the nested class at package-private scope level is not the only thing the compiler did in the above example. It also changed the scope of the nested class itself from the private setting in code to package-private in the
The class, Rogue, attempts to access some of the NestedClass synthetic methods. Its source code is shown next, followed by the compiler error seen when trying to compile this Rogue source code.
Rogue.java trying to access synthetic methods at compile time
The above code will not compile, even for the non-synthetic method
As the above compilation error message indicates, even the non-synthetic method on the nested class is inaccessible at compile time because the nested class has private scope. In his article Java Insecurities: Accounting for Subtleties That Can Compromise Code, Charlie Lai discusses potential situations in which these compiler-introduced changes are security vulnerabilities. Faisal Feroz goes further and states, in the post How to Write Secure Java Code, "Don’t use Inner Classes" (see Nested, Inner, Member, and Top-Level Classes for details on inner classes as a subset of nested classes).
Many of us can go for a long time in Java development without needing significant understanding of synthetic methods. However, there are situations when awareness of these is important. Besides security issues related to these, it is also to be aware of what they are when reading stack traces. Method names such as
The Java Language Specification (section 13.1) states "Any constructs introduced by the compiler that do not have a corresponding construct in the source code must be marked as synthetic, except for default constructors and the class initialization method." Further clues as to the meaning of synthetic in Java can be found in the Javadoc documentation for Member.isSynthetic(). That method's documentation states that it returns "true if and only if this member was introduced by the compiler." I like that very short definition of "synthetic": a Java construct introduced by the compiler.
The Java compiler must create synthetic methods on nested classes when their attributes specified with the private modifier are accessed by the enclosing class. The next code sample indicates this situation.
DemonstrateSyntheticMethods.java (Enclosing Class Invokes One Nested Class Private Attribute)
package dustin.examples;
import java.util.Calendar;
import static java.lang.System.out;
public final class DemonstrateSyntheticMethods
{
public static void main(final String[] arguments)
{
DemonstrateSyntheticMethods.NestedClass nested =
new DemonstrateSyntheticMethods.NestedClass();
out.println("String: " + nested.highlyConfidential);
}
private static final class NestedClass
{
private String highlyConfidential = "Don't tell anyone about me";
private int highlyConfidentialInt = 42;
private Calendar highlyConfidentialCalendar = Calendar.getInstance();
private boolean highlyConfidentialBoolean = true;
}
}
The above code compiles without incident. When javap is run against the compiled
.class file, the output is as shown in the following screen snapshot.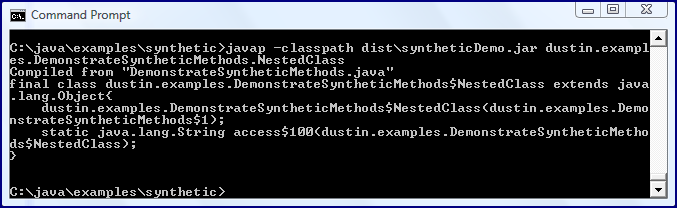
As the above screen snapshot indicates, a synthetic method with the name
access$100 has been created on the nested class NestedClass to provide its private String to the enclosing class. Note that the synthetic method is only added for the single private attribute of the NestedClass that the enclosing class accesses. If I change the enclosing class to access all private attributes of NestedClass, additional synthetic methods will be generated. The next code example demonstrates doing just this and the screen snapshot following it proves that four synthetic methods are generated in that case.DemonstrateSyntheticMethods.java (Enclosing Class Invokes Four Nested Class Private Attributes)
package dustin.examples;
import java.util.Calendar;
import static java.lang.System.out;
public final class DemonstrateSyntheticMethods
{
public static void main(final String[] arguments)
{
DemonstrateSyntheticMethods.NestedClass nested =
new DemonstrateSyntheticMethods.NestedClass();
out.println("String: " + nested.highlyConfidential);
out.println("Int: " + nested.highlyConfidentialInt);
out.println("Calendar: " + nested.highlyConfidentialCalendar);
out.println("Boolean: " + nested.highlyConfidentialBoolean);
}
private static final class NestedClass
{
private String highlyConfidential = "Don't tell anyone about me";
private int highlyConfidentialInt = 42;
private Calendar highlyConfidentialCalendar = Calendar.getInstance();
private boolean highlyConfidentialBoolean = true;
}
}

As the previous two code snippets above and the associated images show, the Java compiler introduces synthetic methods on an as-needed basis. When only one of the nested class's private attributes was accessed by the enclosing class, only one synthetic method (
access$100) was created by the compiler. However, when all four private attributes of the nested class were accessed by the enclosing class, four corresponding synthetic methods were generated by the compiler (access$100, access$200, access$300, and access$400).In all cases of an enclosing class accessing its nested class's private data, a synthetic method was created to allow that access to happen. What happens when the nested class provides an accessor for its private data that the enclosing class can use? That is demonstrated in the next code listing and in its output as shown in the next screen snapshot.
DemonstrateSyntheticMethods.java with Nested Class Public Accessor for Private Data
package dustin.examples;
import java.util.Calendar;
import java.util.Date;
import static java.lang.System.out;
public final class DemonstrateSyntheticMethods
{
public static void main(final String[] arguments)
{
DemonstrateSyntheticMethods.NestedClass nested =
new DemonstrateSyntheticMethods.NestedClass();
out.println("String: " + nested.highlyConfidential);
out.println("Int: " + nested.highlyConfidentialInt);
out.println("Calendar: " + nested.highlyConfidentialCalendar);
out.println("Boolean: " + nested.highlyConfidentialBoolean);
out.println("Date: " + nested.getDate());
}
private static final class NestedClass
{
private String highlyConfidential = "Don't tell anyone about me";
private int highlyConfidentialInt = 42;
private Calendar highlyConfidentialCalendar = Calendar.getInstance();
private boolean highlyConfidentialBoolean = true;
private Date date = new Date();
public Date getDate()
{
return this.date;
}
}
}

The above screen snapshot demonstrates that the compiler did not need to generate a synthetic method for accessing the private Date attribute in the nested class because the enclosing class accessed that attribute via the provided
getDate() method. Even with getDate() provided, the compiler would have generated a synthetic method for accessing the date has the enclosing code been written to access the date attribute directly (as a property) rather than via the accessor method.The last screen snapshot brings up another observation. As the newly added
getDate() method shows in that screen snapshot, modifiers such as public are included in javap output. Because no modifier is shown for the synthetic methods created by the compiler, we know that they are package level (or package-private). In short, the compiler has created package-private methods for accessing private attributes.The Java reflection APIs provide another approach for determining synthetic methods. The next code listing is for a Groovy script that will use the Java reflection APIs to conveniently provide details regarding the methods of the nested class shown above.
reflectOnMethods.groovy
#!/usr/bin/env groovy
import java.lang.reflect.Method
import java.lang.reflect.Modifier
if (args == null || args.size() < 2)
{
println "Outer and nested class names must be provided."
println "\nUsage #1: reflectOnMethods qualifiedOuterClassName nestedClassName\n"
println "\nUsage #2: groovy -cp classpath reflectOnMethods.groovy qualifiedOuterClassName nestedClassName\n"
println "\t1. Include outer and nested classes on classpath if necessary"
println "\t2. Do NOT include \$ on front of nested class name.\n"
System.exit(-1)
}
def enclosingClassName = args[0]
def nestedClassName = args[1]
def fullNestedClassName = enclosingClassName + '$' + nestedClassName
def enclosingClass = Class.forName(enclosingClassName)
Class nestedClass = null
enclosingClass.declaredClasses.each
{
if (!nestedClass && fullNestedClassName.equals(it.name))
{
nestedClass = it
}
}
if (nestedClass == null)
{
println "Unable to find nested class ${fullNestedClassName}"
System.exit(-2)
}
// Use declaredMethods because don't care about inherited methods
nestedClass.declaredMethods.each
{
print "\nMethod '${it.name}' "
print "is ${getScopeModifier(it)} scope, "
print "${it.synthetic ? 'is synthetic' : 'is NOT synthetic'}, and "
println "${it.bridge ? 'is bridge' : 'is NOT bridge'}."
}
def String getScopeModifier(Method method)
{
def modifiers = method.modifiers
def isPrivate = Modifier.isPrivate(modifiers)
def isPublic = Modifier.isPublic(modifiers)
def isProtected = Modifier.isProtected(modifiers)
String scopeString = "package-private" // default
if (isPublic)
{
scopeString = "public"
}
else if (isProtected)
{
scopeString = "protected"
}
else if (isPrivate)
{
scopeString = "private"
}
return scopeString
}
When the above Groovy script is executed against the class and nested class shown above, the output is that shown in the next screen snapshot.
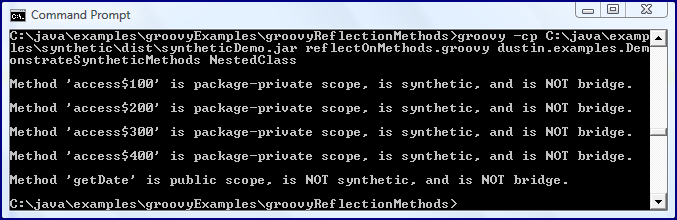
The results of the Groovy script shown in the previous image verify what javap had already told us: there are four synthetic methods and one non-synthetic method defined on the nested class
NestedClass. The script also tells us that the compiler-generated synthetic methods are package-private scope.The addition of synthetic methods to the nested class at package-private scope level is not the only thing the compiler did in the above example. It also changed the scope of the nested class itself from the private setting in code to package-private in the
.class file. Indeed, while the synthetic methods were only added in the case where the enclosing class accessed the private attribute, the compiler always makes the nested class package-private even if it's specified as private in the code. The good news is that this is a resulting artifact of the compilation process, meaning that code cannot be compiled as-is against the changed scope level of the nested class or its synthetic methods. Runtime is where things can get dicey.The class, Rogue, attempts to access some of the NestedClass synthetic methods. Its source code is shown next, followed by the compiler error seen when trying to compile this Rogue source code.
Rogue.java trying to access synthetic methods at compile time
package dustin.examples;
import static java.lang.System.out;
public class Rogue
{
public static void main(final String[] arguments)
{
out.println(DemonstrateSyntheticMethods.NestedClass.getDate());
}
}
The above code will not compile, even for the non-synthetic method
getDate(), and reports this error:Buildfile: C:\java\examples\synthetic\build.xml
-init:
compile:
[javac] Compiling 1 source file to C:\java\examples\synthetic\classes
[javac] C:\java\examples\synthetic\src\dustin\examples\Rogue.java:9: dustin.examples.DemonstrateSyntheticMethods.NestedClass has private access in dustin.examples.DemonstrateSyntheticMethods
[javac] out.println(DemonstrateSyntheticMethods.NestedClass.getDate());
[javac] ^
[javac] 1 error
BUILD FAILED
C:\java\examples\synthetic\build.xml:29: Compile failed; see the compiler error output for details.
Total time: 1 second
As the above compilation error message indicates, even the non-synthetic method on the nested class is inaccessible at compile time because the nested class has private scope. In his article Java Insecurities: Accounting for Subtleties That Can Compromise Code, Charlie Lai discusses potential situations in which these compiler-introduced changes are security vulnerabilities. Faisal Feroz goes further and states, in the post How to Write Secure Java Code, "Don’t use Inner Classes" (see Nested, Inner, Member, and Top-Level Classes for details on inner classes as a subset of nested classes).
Many of us can go for a long time in Java development without needing significant understanding of synthetic methods. However, there are situations when awareness of these is important. Besides security issues related to these, it is also to be aware of what they are when reading stack traces. Method names such as
access$100, access$200, access$300, access$400, access$500, access$600, and access$1000 in the stack trace reflect synthetic methods generated by the compiler.
Friday, October 15, 2010
Modernizr: A Handy HTML5 Tool
One of the most frustrating things about HTML development over the years has been dealing with browser idiosyncrasies and differences. We've been forced to litter our code with detection scripts. As we move toward HTML5, these same issues must be dealt with. Modernizr is a handy tool that reduces some of the difficulties involved in applying HTML5 features across multiple browsers. Even the main web page for Modernizr is helpful in HTML5 development because it uses its own JavaScript library to indicate which features the web browser rendering that page supports.

The following four screen snapshots demonstrate which features Modernizr reports are covered by the Windows versions of the four web browsers: Google Chrome 6.0, Firefox 3.6.10, Microsoft Internet Explorer 8, and Apple Safari 5.0.2. The green checks next to the features indicate that Modernizr reports that feature to be supported by the web browser being used.
Google Chrome Feature Support Reported by Modernizr

Firefox Feature Support Reported by Modernizr

Internet Explorer Feature Support Reported by Modernizr

Safari Feature Support Reported by Modernizr

As the above screen snapshots indicate, Microsoft Internet Explorer 8 lags well behind the other three web browsers in terms of modern feature support. Microsoft Internet Explorer 9 is expected to reduce the gap in modern feature functionality.
As demonstrated in the above screen snapshots, Modernizr is useful in quickly ascertaining which features are supported in each browser. However, Modernizr's real power comes in applying it within web applications for simple and convenient feature detection rather than writing custom feature detection JavaScript code. Modernizr simplifies feature detection, which is generally preferable (as documented here) to user agent detection (AKA browser detection). Developers can include calls to the small Modernizr JavaScript library to reliably detect which features are available in a particular browser.
The following four screen snapshots demonstrate which features Modernizr reports are covered by the Windows versions of the four web browsers: Google Chrome 6.0, Firefox 3.6.10, Microsoft Internet Explorer 8, and Apple Safari 5.0.2. The green checks next to the features indicate that Modernizr reports that feature to be supported by the web browser being used.
Google Chrome Feature Support Reported by Modernizr

Firefox Feature Support Reported by Modernizr

Internet Explorer Feature Support Reported by Modernizr

Safari Feature Support Reported by Modernizr

As the above screen snapshots indicate, Microsoft Internet Explorer 8 lags well behind the other three web browsers in terms of modern feature support. Microsoft Internet Explorer 9 is expected to reduce the gap in modern feature functionality.
As demonstrated in the above screen snapshots, Modernizr is useful in quickly ascertaining which features are supported in each browser. However, Modernizr's real power comes in applying it within web applications for simple and convenient feature detection rather than writing custom feature detection JavaScript code. Modernizr simplifies feature detection, which is generally preferable (as documented here) to user agent detection (AKA browser detection). Developers can include calls to the small Modernizr JavaScript library to reliably detect which features are available in a particular browser.
Monday, October 11, 2010
IBM and Oracle Are Behind OpenJDK!
Years from now, when we all bore our grandchildren with stories of the history of the Java programming language, the date of 11 October 2010 may be considered a landmark date in Java's history. For on that date, the two biggest players in all of Javadom agreed to collaborate on OpenJDK. In this post, I briefly look at the long and winding road that got us here (see The Java History Timeline for additional details).
1991 Project Green
1992 Programming language is called "Oak" (sadly also marked Johnny Carson's exit from late night television's The Tonight Show)
1995 "Oak" renamed to "Java"
1996 First JavaOne Conference and JDK 1.0 (Java Development Kit) released
1997 JDK 1.1 released
1998 Java Community Process (JCP) formalized and JDK 1.2 released
2000 Apple commits to Java support at 2000 JavaOne and JDK 1.3 (Kestrel) released
2002 JDK 1.4.0 (Merlin) and JDK 1.4.1 (Hopper) released
2003 JDK 1.4.2 (Mantis) released
2004 J2SE 5 (Tiger/1.5.0) released along with version naming change
2005 Apache Harmony announced as an open source and free Java implementation
2006 Java SE 6 (1.6.0) released and Sun begins open sourcing Java
2007 OpenJDK comes to life
2009 Oracle purchases Sun (and Java) after IBM attempt to purchase Sun falls through
2010 Oracle sues Google over Android platform, Google boycotts JavaOne 2010, and IBM and Oracle announce IBM's commitment to collaborating on OpenJDK development
Today's announcement that IBM will collaborate on OpenJDK comes at an important time for the Java community. For years, Java developers wondered if Sun would ever open source Java. Recently, some have questioned Oracle's commitment to open source. Today's announcement may mean the most support for OpenJDK since its announcement with two major and well-funded sponsors in Oracle and IBM. It also appears to solidify Oracle's commitment to an open source Java. It is certainly in IBM's interest to have an open source Java, but it also can aid Oracle in terms of credibility in the Java community. OpenJDK offers one of those proverbial "win-win" situations for these two companies, but should benefit the rest of us "little people" as well.
The timing of this announcement was important. As the press release states, this announcement may reassure individuals and organizations who have invested significantly in Java-based applications. It may similarly reassure potential future customers. In addition, this announcement can be interpreted as a sign of how Oracle intends to fulfill its commitment to an open source Java. This is certainly a major announcement that should please most Java developers.
With an open source version of Java supported by the two largest players in the Java space available now, there will be some questions about the future of Apache Harmony. Choice is always preferable, but that doesn't necessarily mean the demand will be great enough to justify the effort. Indeed, Bob Sutor's post IBM Joins the OpenJDK Community, will help unify open source Java efforts states the following:
Overall, it's nice to see some news in the Java world related to convergence rather than divergence.
Related Resources
There are too many related posts and articles related to this announcement to list here, but I do list a few as a sample.
1991 Project Green
1992 Programming language is called "Oak" (sadly also marked Johnny Carson's exit from late night television's The Tonight Show)
1995 "Oak" renamed to "Java"
1996 First JavaOne Conference and JDK 1.0 (Java Development Kit) released
1997 JDK 1.1 released
1998 Java Community Process (JCP) formalized and JDK 1.2 released
2000 Apple commits to Java support at 2000 JavaOne and JDK 1.3 (Kestrel) released
2002 JDK 1.4.0 (Merlin) and JDK 1.4.1 (Hopper) released
2003 JDK 1.4.2 (Mantis) released
2004 J2SE 5 (Tiger/1.5.0) released along with version naming change
2005 Apache Harmony announced as an open source and free Java implementation
2006 Java SE 6 (1.6.0) released and Sun begins open sourcing Java
2007 OpenJDK comes to life
2009 Oracle purchases Sun (and Java) after IBM attempt to purchase Sun falls through
2010 Oracle sues Google over Android platform, Google boycotts JavaOne 2010, and IBM and Oracle announce IBM's commitment to collaborating on OpenJDK development
Today's announcement that IBM will collaborate on OpenJDK comes at an important time for the Java community. For years, Java developers wondered if Sun would ever open source Java. Recently, some have questioned Oracle's commitment to open source. Today's announcement may mean the most support for OpenJDK since its announcement with two major and well-funded sponsors in Oracle and IBM. It also appears to solidify Oracle's commitment to an open source Java. It is certainly in IBM's interest to have an open source Java, but it also can aid Oracle in terms of credibility in the Java community. OpenJDK offers one of those proverbial "win-win" situations for these two companies, but should benefit the rest of us "little people" as well.
The timing of this announcement was important. As the press release states, this announcement may reassure individuals and organizations who have invested significantly in Java-based applications. It may similarly reassure potential future customers. In addition, this announcement can be interpreted as a sign of how Oracle intends to fulfill its commitment to an open source Java. This is certainly a major announcement that should please most Java developers.
With an open source version of Java supported by the two largest players in the Java space available now, there will be some questions about the future of Apache Harmony. Choice is always preferable, but that doesn't necessarily mean the demand will be great enough to justify the effort. Indeed, Bob Sutor's post IBM Joins the OpenJDK Community, will help unify open source Java efforts states the following:
IBM will work with Oracle and the Java community to make OpenJDK the primary high performance open source runtime for Java. IBM will be shifting its development effort from the Apache Project Harmony to OpenJDK. ... We think this is the pragmatic choice. It became clear to us that first Sun and then Oracle were never planning to make the important test and certification tests for Java, the Java SE TCK, available to Apache. We disagreed with this choice, but it was not ours to make. So rather than continue to drive Harmony as an unofficial and uncertified Java effort, we decided to shift direction and put our efforts into OpenJDK.I am also curious (and I'm not the only one) to see if Google will elect to join the OpenJDK and JCP processes or continue to go it alone. The Googling Google blog looks at the relationship between Oracle, IBM, and Google related to today's announcement in the post IBM and Oracle vs. Android? Good luck with that.
Overall, it's nice to see some news in the Java world related to convergence rather than divergence.
Related Resources
There are too many related posts and articles related to this announcement to list here, but I do list a few as a sample.
Saturday, October 9, 2010
Seven Indispensable NetBeans Java Hints
I have found NetBeans Java Hints to be extremely useful in Java development. In this blog post I look at NetBeans Java Hints that I deem indispensable in Java development. I will be using NetBeans 6.9 for the screen snapshots in this post. As this Wiki page indicates, there are numerous hints new to NetBeans 6.9.
The NetBeans IDE makes it easier to control which hints are enabled. This granular level of control is desirable because not every hint is created equal. Some hints, in my opinion, should always be enabled and these are the subject of this post. Other hints, may not be quite as useful for general use and some might even get in the way. I like to have only the hints that matter enabled so that I have a better chance of clearing the yellow highlighting and margin marks that indicate a warning condition. I like to have a "clean" Java source file in NetBeans so that if any significant conditions are introduced, the emergence of yellow tips me off. It is nice to disable less important (to me) hints so that this clean IDE view of the source can be maintained.
It is easy to enable Java hints in NetBeans. Select "Tools" from the title bar, then select "Options" from the drop-down menu. Choose the "Editor" option and then select the "Hints" tab. At this point, make sure that the "Language" drop-down is set to "Java" (other choices include PHP, JavaScript, and Ruby). The screen snapshot below shows how this appears, including the twenty-four categories of hints. The + sign to the left of each hints category can be clicked on to expand it and see specific hints within each category. These can then be selected to have them enabled in the IDE.

One of the categories of hints is "Standard Javac warnings." These are the warnings that I discussed in my blog post javac -Xlint Options. As I stated in that post, some of these can bring a developer's attention to some important conditions in the Java code. In particular, the support for striking out deprecated code marked with @deprecated and @Deprecated is useful in keeping new code from using deprecated methods. The next screen snapshot shows these "Standard Javac warnings."

In this post, I won't look at any of NetBeans' hints in this "Standard Javac warnings" hints category because they are covered by
It is arguable which is the "most important" of the NetBeans hints, but the hint for "suspicious method call" certainly should be high on anyone's list. This hint, which falls under "Probable Bugs" hints category, warns about the dangerous (more than suspicious in my mind) situation I described in the blog post The Contains Trap in Java Collections. The following code snippet shows code that causes this hint to lead to three warnings.
With the "suspicious method call" hint enabled as a warning, NetBeans clearly flags the three occurrences of this situation in the code above as demonstrated in the next image.

As the above screen snapshot indicates, NetBeans flags the three "suspicious method calls" that occur in the code. They are highlighted with yellow underlining and with yellow marks in the right margin. The light bulb icons on the left can be clicked on to see more details and potential resolution options.
In this case, I find this condition of significant enough concern that a warning is not sufficient. NetBeans allows me to specify that this hint results in an error instead of a warning. For example, I can click on the light bulb icon and select "Configure 'Suspicious method call' Hint" option to change it. The new screen is shown next.

With the "Show As" drop-down set to "Error," NetBeans now shows this significant issue as an error in the IDE! This is shown in the next screen snapshot, which is the same as above, but with error-level markings.

Setting the "suspicious method calls" hint to appear as error rather than warning helps make it even more obvious in large code bases. Although I won't specifically show this transition for each NetBeans hint to "error" in this post, it is not surprising that many of these "indispensable" hints could arguably be set to "error" rather than "warning" for NetBeans reporting. NetBeans gives us the flexibility to select which hints we want flagged and which hints we want flagged as errors versus as warnings. One important observation is that NetBeans's treatment of a hint as an error is only for viewing and does not prevent NetBeans from building the source code successfully.
An important NetBeans hint is the "Comparing Strings using

Another dangerous problem occurs when a constructor calls a method on the same class that might be overridden by child method. This is demonstrated in the next code snippet, but fortunately NetBeans can identify this bad behavior with the "Overridable method call in constructor" hint.
Not surprisingly, the "Probable Bugs" category of NetBeans hints has numerous hints that warn of potentially serious complications. For example, the ".equals on incompatible types" hint will be triggered by the following code snippet.
This hint is in many ways like the "suspicious method call" hint covered earlier. Both of these hints warn about cases where the fact that the API necessarily needs to accept an Object instance leaves open the possibility of passing in types that simply can never match what is expected.
I always prefer to know about code issues as early as possible in the development cycle as possible. Specifically, when possible, I'd rather know about code that's flat-out wrong at compile time rather than at runtime. NetBeans includes several hints that let me know of a problem in my code that I'd otherwise not know about until runtime. I've already covered some of these above (the "suspicious method call" and ".equals on incompatible type" hints are two such examples), but the Probable Bugs category of hints provides another particularly useful hint in the "Incompatible Cast/Incompatible instanceof" hint.
This "Class is incompatible with instance of" hint notifies the developer that the type being checked in an outer instanceof operator check is not the same type (and is not compatible with) the type being cast when the instanceof evaluates to true. This is important because the compiler does not report an error or warning in this case. Instead, the problem is not encountered until runtime when a ClassCastException is thrown when the cast attempts to an incompatible type. A code snippet that will trigger this NetBeans hint is shown next.
The above, when seen in NetBeans, looks like what is shown in the next screen snapshot.

The warning provided by NetBeans above about the cast type being incompatible with the type checked by the

A third NetBeans hint from the Probable Bugs category is the "Incorrect Column Index in ResultSet" hint. Unlike many Java (and C/C++) based APIs, the columns in a result set accessed by column number are one-based rather than zero-based. A developer might accidentally (or out of habit) attempt to use a zero-based column index scheme. The next code sample shows how this might be done.
This NetBeans hint is also brought up for negative column indices, but that is less likely to happen then the use of a zero. This code will correctly compile, but will break at runtime with an SQLException ("Invalid column index"). Thankfully, NetBeans warns of this "probable bug" as shown in the next screen snapshot.

It is important to always provide an explicitly overridden hashCode() implementation when equals() is explicitly overridden for correct behavior. NetBeans provides a hint for this. The "Generate missing hashCode or equals" hint will warn if either of these two methods exists without the other. This is demonstrated in the following code sample and the image following the code sample shows NetBeans calling attention to the missing hashCode().

This image shows two NetBeans hints in action. The first is the "Generate missing hashCode()" hint because there is an
I've covered many aspects of NetBeans hints in this post. The ability to flag issues at compilation (or even before that) time rather than at runtime is very helpful. There are other tools that can do this, but it's really nice to have it incorporated and automatically implied directly in the IDE. Furthermore, the ability to select only those hints that are desired is useful and the ability to indicate whether a particular hint should be treated as a warning or error adds further control to the granularity of the hinting reporting. Finally, the ultimate flexibility is provided by the ability to create custom NetBeans hints, something I have not demonstrated in this post. With NetBeans 6.9 introducing so many useful hints, I'm finding reduced need of other static analysis tools.
NetBeans provides many useful hints that improve the quality, correctness, reliability, and maintainability of Java code. In this post, I've focused on some of them that I find particularly valuable. They are summarized here:
The NetBeans IDE makes it easier to control which hints are enabled. This granular level of control is desirable because not every hint is created equal. Some hints, in my opinion, should always be enabled and these are the subject of this post. Other hints, may not be quite as useful for general use and some might even get in the way. I like to have only the hints that matter enabled so that I have a better chance of clearing the yellow highlighting and margin marks that indicate a warning condition. I like to have a "clean" Java source file in NetBeans so that if any significant conditions are introduced, the emergence of yellow tips me off. It is nice to disable less important (to me) hints so that this clean IDE view of the source can be maintained.
It is easy to enable Java hints in NetBeans. Select "Tools" from the title bar, then select "Options" from the drop-down menu. Choose the "Editor" option and then select the "Hints" tab. At this point, make sure that the "Language" drop-down is set to "Java" (other choices include PHP, JavaScript, and Ruby). The screen snapshot below shows how this appears, including the twenty-four categories of hints. The + sign to the left of each hints category can be clicked on to expand it and see specific hints within each category. These can then be selected to have them enabled in the IDE.

One of the categories of hints is "Standard Javac warnings." These are the warnings that I discussed in my blog post javac -Xlint Options. As I stated in that post, some of these can bring a developer's attention to some important conditions in the Java code. In particular, the support for striking out deprecated code marked with @deprecated and @Deprecated is useful in keeping new code from using deprecated methods. The next screen snapshot shows these "Standard Javac warnings."

In this post, I won't look at any of NetBeans' hints in this "Standard Javac warnings" hints category because they are covered by
javac's -Xlint. Instead, I focus in this post on warnings that NetBeans hints provide that are not available via javac. Indeed, NetBeans provides some handy warnings for some very dangerous ("suspicious") conditions that I wish the standard compiler warned me about!It is arguable which is the "most important" of the NetBeans hints, but the hint for "suspicious method call" certainly should be high on anyone's list. This hint, which falls under "Probable Bugs" hints category, warns about the dangerous (more than suspicious in my mind) situation I described in the blog post The Contains Trap in Java Collections. The following code snippet shows code that causes this hint to lead to three warnings.
/**
* This method demonstrates the NetBeans "Suspicious method call" hint.
*/
private void demonstrateSuspiciousMethodsCalls()
{
final StringBuilder builder = new StringBuilder();
builder.append("Hints");
final Set<String> strings = new HashSet<String>();
strings.add("NetBeans");
strings.add("Hints");
strings.add("http://marxsoftware.blogspot.com/");
if (strings.contains(builder))
{
out.println("That String is contained!");
}
else
{
out.println("That String is NOT contained.");
}
final Map<String, String> stringsMap = new HashMap<String, String>();
stringsMap.put("One", "NetBeans");
stringsMap.put("Two", "Hints");
stringsMap.put("Three", "http://marxsoftware.blogspot.com/");
if (stringsMap.containsKey(builder))
{
stringsMap.remove(builder);
}
}
With the "suspicious method call" hint enabled as a warning, NetBeans clearly flags the three occurrences of this situation in the code above as demonstrated in the next image.

As the above screen snapshot indicates, NetBeans flags the three "suspicious method calls" that occur in the code. They are highlighted with yellow underlining and with yellow marks in the right margin. The light bulb icons on the left can be clicked on to see more details and potential resolution options.
In this case, I find this condition of significant enough concern that a warning is not sufficient. NetBeans allows me to specify that this hint results in an error instead of a warning. For example, I can click on the light bulb icon and select "Configure 'Suspicious method call' Hint" option to change it. The new screen is shown next.

With the "Show As" drop-down set to "Error," NetBeans now shows this significant issue as an error in the IDE! This is shown in the next screen snapshot, which is the same as above, but with error-level markings.

Setting the "suspicious method calls" hint to appear as error rather than warning helps make it even more obvious in large code bases. Although I won't specifically show this transition for each NetBeans hint to "error" in this post, it is not surprising that many of these "indispensable" hints could arguably be set to "error" rather than "warning" for NetBeans reporting. NetBeans gives us the flexibility to select which hints we want flagged and which hints we want flagged as errors versus as warnings. One important observation is that NetBeans's treatment of a hint as an error is only for viewing and does not prevent NetBeans from building the source code successfully.
An important NetBeans hint is the "Comparing Strings using
== or != hint. This hint flags the well-known issue in Java when Strings (usually mistakenly) are compared using == or != instead of .equals. The danger is increased dramatically when coupled with String instantiations using the new keyword and that's what NetBeans's "String constructor" hint catches. The next code snippet leads to these two hints being triggered. The NetBeans response to that code is shown after the code./**
* This method demonstrates two NetBeans hints: comparing strings with == or
* != and string constructor initialization. These two suspicious cases are
* especially problematic when they exist together as demonstrated in this
* method.
*/
private void demonstrateComparingStringsAndStringConstructorInitialization()
{
final String stringOne = new String("NetBeans");
final String stringTwo = new String("NetBeans");
if (stringOne == stringTwo)
{
out.println(stringOne + " equals " + stringTwo + ".");
}
else
{
out.println(stringOne + " does NOT equal " + stringTwo + ".");
}
}

Another dangerous problem occurs when a constructor calls a method on the same class that might be overridden by child method. This is demonstrated in the next code snippet, but fortunately NetBeans can identify this bad behavior with the "Overridable method call in constructor" hint.
package dustin.examples;
/**
* This class is full of misbehavior to help demonstrate NetBeans hints.
*/
public class MisbehavingClass
{
/**
* This constructor does a bad thing: it calls an overridable method.
*/
public MisbehavingClass()
{
initialize();
}
protected void initialize()
{
// do some initialization
}
}
Not surprisingly, the "Probable Bugs" category of NetBeans hints has numerous hints that warn of potentially serious complications. For example, the ".equals on incompatible types" hint will be triggered by the following code snippet.
/**
* Demonstrate NetBeans ".equals on incompatible types" hint.
*/
private void demonstrateIncompatibleEquals()
{
final String string = "String";
final StringBuilder builder = new StringBuilder("String");
if (string.equals(builder))
{
out.println(string + " equals " + builder);
}
else
{
out.println(string + " is NOT equal to " + builder);
}
}
This hint is in many ways like the "suspicious method call" hint covered earlier. Both of these hints warn about cases where the fact that the API necessarily needs to accept an Object instance leaves open the possibility of passing in types that simply can never match what is expected.
I always prefer to know about code issues as early as possible in the development cycle as possible. Specifically, when possible, I'd rather know about code that's flat-out wrong at compile time rather than at runtime. NetBeans includes several hints that let me know of a problem in my code that I'd otherwise not know about until runtime. I've already covered some of these above (the "suspicious method call" and ".equals on incompatible type" hints are two such examples), but the Probable Bugs category of hints provides another particularly useful hint in the "Incompatible Cast/Incompatible instanceof" hint.
This "Class is incompatible with instance of" hint notifies the developer that the type being checked in an outer instanceof operator check is not the same type (and is not compatible with) the type being cast when the instanceof evaluates to true. This is important because the compiler does not report an error or warning in this case. Instead, the problem is not encountered until runtime when a ClassCastException is thrown when the cast attempts to an incompatible type. A code snippet that will trigger this NetBeans hint is shown next.
/**
* Demonstrate NetBeans hint "Cast is incompatible with given instanceof".
*/
private void demonstrateCastIncompatibleWithInstanceOf()
{
final Object stringBuilder = new StringBuilder("string");
if (stringBuilder instanceof String)
{
final StringBuilder newBuilder = (StringBuilder) stringBuilder;
out.println("StringBuilder: " + newBuilder);
}
else if (stringBuilder instanceof StringBuilder)
{
final String newString = (String) stringBuilder;
out.println("String: " + newString);
}
}
The above, when seen in NetBeans, looks like what is shown in the next screen snapshot.

The warning provided by NetBeans above about the cast type being incompatible with the type checked by the
instanceof operator is much nicer (and much sooner) than when first encountered in runtime:
A third NetBeans hint from the Probable Bugs category is the "Incorrect Column Index in ResultSet" hint. Unlike many Java (and C/C++) based APIs, the columns in a result set accessed by column number are one-based rather than zero-based. A developer might accidentally (or out of habit) attempt to use a zero-based column index scheme. The next code sample shows how this might be done.
/**
* Demonstrate NetBeans hint related to incorrect column index used with
* JDBC {@code ResultSet}.
*/
private void demonstrateIncorrectColumnIndexInResultSet()
{
final String jdbcUrl = "jdbc:oracle:thin:@localhost:1521:orcl";
final String jdbcDriverName = "oracle.jdbc.pool.OracleDataSource";
final String queryStr = "select employee_id, last_name, first_name from employees";
try
{
Class.forName("oracle.jdbc.pool.OracleDataSource");
final Connection connection = DriverManager.getConnection(jdbcUrl, "hr", "hr");
final PreparedStatement statement = connection.prepareStatement(queryStr);
final ResultSet rs = statement.executeQuery();
while (rs.next())
{
final int id = rs.getInt(0); // BAD FORM!!!
final String lastName = rs.getString(1);
final String firstName = rs.getString(2);
out.println(firstName + " " + lastName + "'s ID is " + id + ".");
}
}
catch (ClassNotFoundException cnfEx)
{
out.println(
"Cannot find JDBC driver class '" + jdbcDriverName + "' - "
+ cnfEx.toString());
}
catch (SQLException sqlEx)
{
out.println("Don't do this: " + sqlEx.toString());
}
}
This NetBeans hint is also brought up for negative column indices, but that is less likely to happen then the use of a zero. This code will correctly compile, but will break at runtime with an SQLException ("Invalid column index"). Thankfully, NetBeans warns of this "probable bug" as shown in the next screen snapshot.

It is important to always provide an explicitly overridden hashCode() implementation when equals() is explicitly overridden for correct behavior. NetBeans provides a hint for this. The "Generate missing hashCode or equals" hint will warn if either of these two methods exists without the other. This is demonstrated in the following code sample and the image following the code sample shows NetBeans calling attention to the missing hashCode().
public boolean equals(Object obj)
{
if (obj == null)
{
return false;
}
if (this.getClass() != obj.getClass())
{
return false;
}
final MisbehavingClass other = (MisbehavingClass) obj;
return this.variable != null ? this.variable.equals(other.variable) : other.variable == null;
}

This image shows two NetBeans hints in action. The first is the "Generate missing hashCode()" hint because there is an
equals(Object) method, but not a hashCode() method in this class. The second is another useful NetBeans hint that suggests that the developer should "Add @Override Annotation" to this method that overrides Object's hashCode(). I like to have this one turned on to ensure that I don't accidentally override a method that I am not intending to override. If I see this hint, I make sure it is supposed to be an overriding method and add the annotation or else change its name to not be overriding.I've covered many aspects of NetBeans hints in this post. The ability to flag issues at compilation (or even before that) time rather than at runtime is very helpful. There are other tools that can do this, but it's really nice to have it incorporated and automatically implied directly in the IDE. Furthermore, the ability to select only those hints that are desired is useful and the ability to indicate whether a particular hint should be treated as a warning or error adds further control to the granularity of the hinting reporting. Finally, the ultimate flexibility is provided by the ability to create custom NetBeans hints, something I have not demonstrated in this post. With NetBeans 6.9 introducing so many useful hints, I'm finding reduced need of other static analysis tools.
NetBeans provides many useful hints that improve the quality, correctness, reliability, and maintainability of Java code. In this post, I've focused on some of them that I find particularly valuable. They are summarized here:
- Suspicious Method Call
- Comparing Strings Using == or != AND String Constructor
- Overridable Method Call in Constructor
- .equals Incompatible Types
- Incorrect Column Index in ResultSet
- Cast Incompatible with instanceof
- Generate .equals or .hashCode Method
These hints are so useful (almost always a real bug) and it is so advantageous to know about them sooner (compile/pre-compile time rather than runtime), that I'd like to see these be added to Sun's/Oracle's javac's -Xlint options.
New Links to My Oracle Technology Network Articles
I noticed that the URLs to Oracle Technology Network (OTN) articles have changed recently. In this brief post, I list the new URLs for the articles that I have written or co-written that are published on OTN.
Build a Java Application With Eclipse, Spring, and Oracle WebLogic Server (February 2010)
New URL: http://www.oracle.com/technetwork/articles/marx-oepe-spring-095718.html
Former URL: http://www.oracle.com/technology/pub/articles/marx-oepe-spring.html
Basic Java Persistence API Simple Best Practices (May 2008)
New URL: http://www.oracle.com/technetwork/articles/marx-jpa-087268.html
Former URL: http://www.oracle.com/technology/pub/articles/marx-jpa.html
Visualize Your Oracle Database Data with JFreeChart (October 2007)
New URL: http://www.oracle.com/technetwork/articles/marx-jchart-085298.html
Former URL: http://www.oracle.com/technology/pub/articles/marx-jchart.html
Better JPA, Better JAXB, and Better Annotations Processing with Java SE 6 (September 2007)
New URL: http://www.oracle.com/technetwork/articles/marx-jse6-090753.html
Former URL: http://www.oracle.com/technology/pub/articles/marx-jse6.html
Accessorize Oracle Database with Ruby (February 2007)
New URL: http://www.oracle.com/technetwork/articles/marx-ruby-092465.html
Former URL: http://www.oracle.com/technology/pub/articles/marx-ruby.html
Add Some Spring to Your Oracle JDBC Database Access (November 2005)
New URL: Unknown (see this Internet Archive Wayback Machine Copy)
Former URL: http://www.oracle.com/technetwork/articles/marx_spring.html
Build a Java Application With Eclipse, Spring, and Oracle WebLogic Server (February 2010)
New URL: http://www.oracle.com/technetwork/articles/marx-oepe-spring-095718.html
Former URL: http://www.oracle.com/technology/pub/articles/marx-oepe-spring.html
Basic Java Persistence API Simple Best Practices (May 2008)
New URL: http://www.oracle.com/technetwork/articles/marx-jpa-087268.html
Former URL: http://www.oracle.com/technology/pub/articles/marx-jpa.html
Visualize Your Oracle Database Data with JFreeChart (October 2007)
New URL: http://www.oracle.com/technetwork/articles/marx-jchart-085298.html
Former URL: http://www.oracle.com/technology/pub/articles/marx-jchart.html
Better JPA, Better JAXB, and Better Annotations Processing with Java SE 6 (September 2007)
New URL: http://www.oracle.com/technetwork/articles/marx-jse6-090753.html
Former URL: http://www.oracle.com/technology/pub/articles/marx-jse6.html
Accessorize Oracle Database with Ruby (February 2007)
New URL: http://www.oracle.com/technetwork/articles/marx-ruby-092465.html
Former URL: http://www.oracle.com/technology/pub/articles/marx-ruby.html
Add Some Spring to Your Oracle JDBC Database Access (November 2005)
New URL: Unknown (see this Internet Archive Wayback Machine Copy)
Former URL: http://www.oracle.com/technetwork/articles/marx_spring.html
Subscribe to:
Posts (Atom)