One of my annual traditions with this blog is to post a summary of my top ten blog posts of the year in terms of "hits" on the blog post. A post with more hits isn't necessarily better than a post with fewer hits, but the former certainly gets more attention. Some of the top posts in 2010 were not actually written in 2010). For example, the tenth most popular post of 2010 listed here was actually the 16th most accessed post on my blog in 2010. Seven posts from other years had more hits than it! I don't count these in the 2010 Top Ten and don't count them against that 2010 list either. In other words, some of the Top Ten listed here actually weren't among the ten most-accessed blog posts on my blog for the year, but all are the ten most accessed blogged posts on my blog that were written this year.
11. O JavaFX, What Art Thou? (25 May 2010, Overall #16 in 2010)
The post O JavaFX, What Art Thou? enjoys a provocative title and covers a somewhat controversial subject. A DZone link to the syndicated JavaWorld version, a Java.net reference, and multiple tweets helped this post be one of the top ten most popular posts on my blog written in 2010. In this post, I enumerated issues surrounding JavaFX that I believe led to hesitation for Java developers to adopt it. I believe that Oracle has addressed some of these with its JavaOne 2010 announcements related to JavaFX.
10. Interesting Software Development Tidbits - Early May 2010 (3 May 2010, Overall #15 in 2010)
Although I thought I summarized a few interesting points in this blog post, I was still surprised that a "grab bag" type of post like Interesting Software Development Tidbits - Early May 2010 would end up in my top ten. Being featured on Java.net was probably a big part of this.
9. Groovy: Switch on Steroids (21 January 2010, Overall #14 in 2010)
Posts written early in the year obviously have an advantage in terms of garnering the most hits for the year. I also think that Groovy is a pretty popular subject in at least the Java corner of the blogosphere. Other explanations for Groovy: Switch on Steroids's success include a DZone reference to it and its Grails Tutorials reference.
8. The High Cost of Not Asking Questions (17 December 2009, Overall #13 in 2010)
I must admit that the post The High Cost of Not Asking Questions was one of my personal favorite posts in recent months. It turns out it was actually written in 2009, but I counted it as a Top Ten in 2010 because it was posted so late in 2009. The counting of this as a 2010 post is what led me to actually include eleven posts here in this Top Ten of 2010.
7. Effective Exception Handling is Covered Effectively in Effective Java (21 April 2010, Overall #11 in 2010)
There is no question that the Java.net reference to the post Effective Exception Handling is Covered Effectively in Effective Java contributed to the success of this post. In this case, the DZone reference to it doesn't seem to have contributed much in terms of traffic.
6. Dynamic Java Log Levels with JMX/LoggingMXBean, JConsole, VisualVM, and Groovy (1 April 2010, Overall #8 in 2010)
This post is the first listed here to actually be in the Top Ten of 2010 on its own right without filtering out non-2010 posts. It's title is a mouthful filled with buzzwords, which likely contributed to the attention it received. Its DZone reference definitely helped.
5. Reproducing "code too large" Problem in Java (18 January 2010, Overall #7 in 2010)
Although its publication early in 2010 was a benefit, I believe this post's popularity was more likely due to its Java.net reference. Java.net editor Kevin Farnham provided a nice summary of this post and encouraged readers to check it (and my blog in general) out.
4. Ten Best Chapters of Software Development Books (3 April 2010, Overall #6 in 2010)
I thought the idea behind this post (to focus on the best chapters of books rather than best overall books) was at least slightly original and creative. I was happy to see this post well-received in terms of number of hits. As is a theme on this list, the Java.net reference certainly played a part as did posts from other bloggers such as Mihai Fonoage.
3. JAX-RS With Jersey: An Introduction (9 February 2010, Overall #4)
Even its early publication date in 2010 does not solely explain the success of the post JAX-RS With Jersey: An Introduction. I believe that REST and JAX-RS have been particularly popular topics for blog searches in recent years and having "Introduction" in the title probably helped quite a bit. This post was also referenced on Java.net and the JavaWorld syndicated version of it saw minor success as a DZone link.
2. SqlPhobia: The Irrational Fear of SQL (29 March 2010, Overall #2 in 2010)
In retrospect, it is not all that surprising that this post had enough hits to be the second most popular of my posts in 2010 absolutely (no need to differentiate the year of its origin in this case). This post was written relatively early in the year, it included a title that evokes emotion and attention, and it was on a slightly controversial topic with slightly controversial language. Add in to this a strong Java.net reference, a reddit posting, a DZone reference, blogs written as responses, and numerous tweets, and you have a recipe for a blog post that garners significant attention. I like to think this post also was popular because it hit a nerve. Many of the developers who commented on this post had valid reasons that I agree with for using non-SQL solutions, but I still maintain that far too high of a percentage of ORM users are such because of a fear of SQL. That, at least, has been my anecdotal experience from conversations with ORM enthusiasts.
1. I Use Dead Programming Languages
The most popular post on my blog in 2010, I Use Dead Programming Languages, shares many of the traits that made the just-discussed post on Sqlphobia so popular: it had a DZone link (though it was significantly more successful on DZone than the Sqlphobia post), it was referenced on reddit, it had an attention-grabbing title, and it covered a controversial topic.
What Were the Other Five?
The #11 post listed here was actually the sixteenth most accessed post on my blog in 2010. That, of course, means that five posts not written in 2010 were accessed more often than that "#11" post. Here are those posts which have apparently stood the "test of time" fairly well:
Effective Java NullPointerException Handling (25 April 2009, Overall #12 in 2010)
Bare Bones BlazeDS HTTPService Example (9 May 2008, Overall #10 in 2010)
Easy Java-Based REST Testing Tools (3 January 2009, Overall #9 in 2010)
Using RESTClient with Java's HTTPServlet (21 January 2009, Overall #5 in 2010)
Simple Remote JMX with GlassFish (19 May 2008, Overall #3 in 2010)
Conclusions
I was generally pleased with the posts that made the Top Ten. As always, there were posts that I personally felt were better (meaning more work and/or more value in my opinion) than some of these, but all of these were posts that I still stand behind and think are generally worth the read.
It was obvious in this year's Top Ten that social sites such as Java.net, DZone, and reddit programming make a huge difference in which posts get attention. In general, Java-themed posts were most successful for me this year, but I was pleased to see that some posts that are more general than Java did well in 2010.
Friday, December 31, 2010
Wednesday, December 29, 2010
Regular Expressions in Groovy (via Java)
The people who attended my presentations at RMOUG Training Days 2010 asked several good questions. One question that was asked in the Groovy presentation that I really wish I had included a slide on was "Does Groovy support regular expressions?" The focus of my presentation was on using Groovy for scripting, so this was a very natural and relevant question. I answered that Groovy uses Java's regular expression support and adds a few nifty features of its own to make regular expressions easier to apply. In this blog post, I briefly summarize what wish I had dedicated a slide on in that presentation. I do plan to have a slide on and cover Groovy regular expression support in my RMOUG Training Days 2011 presentation "Groovier Java Scripting."
One of my favorite software development quotes concerns regular expressions (see Source of the Famous 'Now You Have Two Problems' Quote for extensive background on this quote):
I personally have a sort of love/hate relationship with regular expressions. Regular expressions almost always allow for more concise code, but that does not always translate to "easier" or "more readable" code. There are times when I feel the regular expression solution is most concise, most elegant, and most readable and then there are the other times ...
There are a few things that make use of regular expressions seem difficult at times. If I use regular expressions regularly, I find myself increasingly fond of them. When I only use regular expressions sporadically, I don't find them as easy. Lack of familiarity with regular expressions syntax due to infrequent use often makes them more difficult to write and read (I typically find them easier to write than read). Another cause of the difficulty in reading and writing regular expressions stems from their very advantage: they can be almost too concise at times (especially when not used often). Finally, even when I get comfortable with regular expressions, it can be a minor annoyance to realize again (often the hard way) that there are multiple dialects of regular expressions and the different dialects have differing syntaxes (Java's regular expression is often said to be Perl-like). These differences make regular expressions less regular.
SIDE NOTE: One of the things I like about the book Regular Expressions Cookbook is that it lists which dialects (it calls them "flavors") of regular expressions work for each recipe (example) in the book. For example, Recipe 2.18 ("Add Comments to a Regular Expression") states that this particular recipe applies to the regular expression "flavors" of Java, Perl, Perl Compatible Regular Expressions, .NET, Python, and Ruby, but does not apply to the JavaScript flavor of regular expressions.
For those of us who used Java and languages (or Unix or Linux or vi) that supported regular expressions, it was welcome news when it was announced that Java would add regular expression support with JDK 1.4.
Although the addition of regular expressions to Java was welcome, Java's regular expression support is not always the easiest to apply due to language requirements of the Java Language Specification. In other words, Java language limitations add another layer of challenge to using regular expressions. Groovy, goes a long way toward reducing this extra complexity of regular expressions in Java.
The Java Tutorials's lesson on regular expressions introduces Java's support for regular expressions via the java.util.regex package and highlights the two classes Pattern and Matcher.
The Java Pattern is described in its Javadoc documentation as "a compiled representation of a regular expression." The documentation further explains that "a regular expression, specified as a string, must first be compiled into an instance of this class [Pattern]." A typical approach for accessing a compiled Pattern instance is to use
The availability of
I use the example provided by Regular Expressions Cookbook Recipe 3.1 ("Literal Regular Expressions in Source Code") to illustrate the advantages of Groovy in
As the Regular Expressions Cookbook recipe explains, this regular expression is represented in Java as
I demonstrate this example more completely with the following simple Java code.
Running the above code leads to the output demonstrated in the next screen snapshot.

Before looking at how Groovy improves on the handling of the regular expression, I round out the Java example that was started above to also include an example of Java's Matcher class in action. The
The third approach is demonstrated in the Java Tutorial on regular expressions. It provides a "test harness" that I have adapted here:
The next screen snapshot demonstrates the output from this adapted Java-based regular expression test harness on the regular expression used above.

This example demonstrates the Matcher.find() method in action: it iterates over the provided input String and returns
The
When the code above is executed (as part of a class and after being invoked), the output appears as shown in the next screen snapshot.

This example confirms what the Javadoc states about the
Whew! It's been a long way getting here, but I've now covered enough Java handling of regular expressions to move onto what Groovy can do with regular expressions.
I mentioned previously that Groovy doesn't require the developer to explicitly instantiate a Pattern instance to get access to one. Instead this can be done implicitly by prefixing a String with the
The Groovy
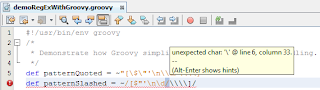
NetBeans 6.9 includes Groovy support and it helps us to see that plopping the escape character-ridden Java String used for a regular expression in the Java example above is actually not allowed in Groovy. Here's what NetBeans 6.9 shows for such a case (note the red squiggly line and the error message; thanks NetBeans!).

The small snippet of code shown above in the NetBeans 6.9 editor window indicates that the dollar sign (
Using the slashy syntax helped avoid the need to escape the
In response to the NetBeans flagged errors, I can fix the regular expression Pattern definitions to get the following Groovy code that creates Pattern instances with both quoted strings and slashy strings:
When the above Groovy script is executed, the output looks like that shown in the next screen snapshot.

The snapshot shows the general advantage in presentation of the slashy syntax as compared to the quoted syntax. The slashy syntax required far less escaping than the quoted syntax or the equivalent Java syntax, making the String closer to the original regular expression.
There is one downside evident from this. Note that the new line
Being required to express the newline as
The next code listing demonstrates Matcher handling in Groovy:
The output from running this, shown in the next screen snapshot, tells the tale.

This output confirms that the Groovy
Mr. Haki provides a nice overview of Groovy's treatment of regular expressions via Matchers in his post Groovy Goodness: Matchers for Regular Expressions. He similarly covers Groovy handling of Patterns in the post Groovy Goodness: Using Regular Expression Pattern Class.
Conclusion
The ability to use more natural-looking (at least by regular expressions standards) regular expressions, the ability to use operators rather than APIs and method calls, and the extra "smarts" added to GDK's extensions of the Java RegEx library make using regular expressions in Groovy easier and more natural to the people who are probably most familiar with regular expressions: script writers. As is true with most of Groovy, Groovy's regular expression support is a reflection of Java's regular expression support. Generally speaking, anything one knows about regular expressions in Java (including the syntax supported in Java's flavor/dialect) can be applied when using regular expressions in Groovy. In several cases, though, Grooy makes it easier to use. With anything, but especially with regular expressions, easier is always better.
Additional Resources
I mentioned previously that there are numerous great online resources on Groovy's support for regular expressions. Some of them are listed here. I especially recommend the first listed resource (Groovy: Don't Fear the RegExp) and book I frequently cited in this post (Regular Expressions Cookbook).
⇒ Regular Expressions Cookbook
⇒ Groovy: Don’t Fear the RegExp
⇒ Groovy Regular Expressions
⇒ Groovy Tutorial 4 - Groovy Regular Expressions Basics
⇒ Groovy Goodness: Using Regular Expression Pattern Class
⇒ Groovy Goodness: Matchers for Regular Expressions
⇒ Big Collection of Regular Expressions (not specific to Groovy)
⇒ Finding Files by Name with Groovy
⇒ Online Regular Expression Test Page (uses java.util.regex)
⇒ RegexBuddy
⇒ RegexPal
⇒ Regular Expression Tool
One of my favorite software development quotes concerns regular expressions (see Source of the Famous 'Now You Have Two Problems' Quote for extensive background on this quote):
Some people, when confronted with a problem, think
"I know, I'll use regular expressions." Now they have two problems.
I personally have a sort of love/hate relationship with regular expressions. Regular expressions almost always allow for more concise code, but that does not always translate to "easier" or "more readable" code. There are times when I feel the regular expression solution is most concise, most elegant, and most readable and then there are the other times ...
There are a few things that make use of regular expressions seem difficult at times. If I use regular expressions regularly, I find myself increasingly fond of them. When I only use regular expressions sporadically, I don't find them as easy. Lack of familiarity with regular expressions syntax due to infrequent use often makes them more difficult to write and read (I typically find them easier to write than read). Another cause of the difficulty in reading and writing regular expressions stems from their very advantage: they can be almost too concise at times (especially when not used often). Finally, even when I get comfortable with regular expressions, it can be a minor annoyance to realize again (often the hard way) that there are multiple dialects of regular expressions and the different dialects have differing syntaxes (Java's regular expression is often said to be Perl-like). These differences make regular expressions less regular.
SIDE NOTE: One of the things I like about the book Regular Expressions Cookbook is that it lists which dialects (it calls them "flavors") of regular expressions work for each recipe (example) in the book. For example, Recipe 2.18 ("Add Comments to a Regular Expression") states that this particular recipe applies to the regular expression "flavors" of Java, Perl, Perl Compatible Regular Expressions, .NET, Python, and Ruby, but does not apply to the JavaScript flavor of regular expressions.
For those of us who used Java and languages (or Unix or Linux or vi) that supported regular expressions, it was welcome news when it was announced that Java would add regular expression support with JDK 1.4.
Although the addition of regular expressions to Java was welcome, Java's regular expression support is not always the easiest to apply due to language requirements of the Java Language Specification. In other words, Java language limitations add another layer of challenge to using regular expressions. Groovy, goes a long way toward reducing this extra complexity of regular expressions in Java.
The Java Tutorials's lesson on regular expressions introduces Java's support for regular expressions via the java.util.regex package and highlights the two classes Pattern and Matcher.
The Java Pattern is described in its Javadoc documentation as "a compiled representation of a regular expression." The documentation further explains that "a regular expression, specified as a string, must first be compiled into an instance of this class [Pattern]." A typical approach for accessing a compiled Pattern instance is to use
Pattern p = Pattern.compile(""); with the relevant regular expression specified within the pair of double quotes. Groovy provide a shortcut here with the ~ symbol. Prefixing a String literal in Groovy with the ~ creates a Pattern instance from that String. This implies that Pattern p = Pattern.compile("a*b"); can be written in Groovy as def p = ~"a*b" (example used in Javadoc for Pattern).The availability of
~ is a speck of syntactic sugar, but Groovy provides more regular expression sweetness than this. One of the least appealing parts of Java's regular expression support is the handling of backslashes within regular expressions. This is really more of a problem of backslash treatment in Java Strings. Groovy makes this much nicer to use by providing the ability to specify the regular expression used in a Pattern with "slashy syntax." This allows regular expressions to appear more natural than they do when the String must be made to comply with Java expectations.I use the example provided by Regular Expressions Cookbook Recipe 3.1 ("Literal Regular Expressions in Source Code") to illustrate the advantages of Groovy in
Pattern representation of a regular expressions. This recipe provides the literal regular expression string [$"'\n\d/\\] for its example and explains what this represents: "This regular expression consists of a single character class that matches a dollar sign, a double quote, a single quote, a line feed, any digit between 0 and 9, a forward slash, or a backslash." The only "escape" character in the entire regular expression is the need for two backslashes to represent that the character can be a single backslash.As the Regular Expressions Cookbook recipe explains, this regular expression is represented in Java as
"[$\"'\n\\d/\\\\]". Ignoring the double quotes on either side of the Java representation, it is still clear that Java String treatment forces the regular expression String [$"'\n\d/\\] to be represented in Java as [$\"'\n\\d/\\\\]. Note that the Java representation must add a backslash in front of the double quote that is part of the regular expression to escape it, must do the same thing for the \d that represents numeric digit, and then must provide four consecutive backslashes at the end to appropriately escape and represent the two that are actually meant for the regular expression. Regular expressions can be cryptic anyway and even the slightest typo can change everything, so the extra syntax needed for the Java version is more that can go wrong.I demonstrate this example more completely with the following simple Java code.
// Regular Expression: [$"'\n\d/\\]
// For Java, must escape the double quote, the \d, and the \\
final String regExCookbook31RegExString = "[$\"'\n\\d/\\\\]";
final Pattern regExCookbook31Pattern = Pattern.compile(regExCookbook31RegExString);
out.println(
"The original regular expression is: "
+ regExCookbook31Pattern.pattern());
Running the above code leads to the output demonstrated in the next screen snapshot.

Before looking at how Groovy improves on the handling of the regular expression, I round out the Java example that was started above to also include an example of Java's Matcher class in action. The
Matcher is obtained from the Pattern instance and supports three types of matching: (1) matching the entire provided sequence against the regular expression pattern [Matcher.matches()], (2) matching at least the beginning portion of the provided sequence against the regular expression pattern [Matcher.lookingAt()], and (3) iterating over the provided sequence looking for one or more pattern matches [Matcher.find()].The third approach is demonstrated in the Java Tutorial on regular expressions. It provides a "test harness" that I have adapted here:
package dustin.examples;
import java.io.Console;
import java.util.regex.Pattern;
import java.util.regex.Matcher;
import static java.lang.System.err;
/**
* Regular expression test harness slightly adapted from example provided in
* Java Tutorial on regular expressions. The location of the original is
* http://download.oracle.com/javase/tutorial/essential/regex/test_harness.html.
*/
public class RegExTestHarness
{
/**
* Simple executable method that provides demonstration of Java's regular
* expression support with java.util.regex package and its classes Pattern
* and Matcher. Adapted from Java Tutorial regular expressions test harness.
*
* @param arguments Command-line arguments: none expected.
*/
public static void main(final String[] arguments)
{
final Console console = System.console();
if (console == null)
{
err.println("No console available; this application requires it.");
System.exit(-1);
}
String regExInput;
do
{
regExInput = console.readLine("%nEnter your regular expression: ");
final Pattern pattern = Pattern.compile(regExInput);
final String searchStringInput =
console.readLine("Enter input string to search with regular expression: ");
final Matcher matcher = pattern.matcher(searchStringInput);
boolean found = false;
while (matcher.find())
{
console.format(
"Text \"%s\" located starting at "
+ "index %d and ending at index %d.%n",
matcher.group(), matcher.start(), matcher.end());
found = true;
}
if (!found)
{
console.format("No match found.%n");
}
} while (!regExInput.isEmpty());
}
}
The next screen snapshot demonstrates the output from this adapted Java-based regular expression test harness on the regular expression used above.
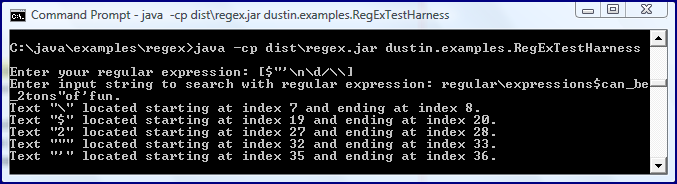
This example demonstrates the Matcher.find() method in action: it iterates over the provided input String and returns
true whenever it evaluates a character that satisfies the single character regular expression. The Java code then uses other methods on Matcher (Matcher.group(), Matcher.start(), and Matcher.end()) to provide more details on the match.The
Matcher.find() method is the best choice when one wants to find and act upon any regular expression matches in a given expression. However, if one is only interested in whether the given expression begins with a match to the regular expression of if the entire expression is an exact match of the regular expression, then Matcher.lookingAt() or Matcher.find() are likely to be preferred. The three methods in the next code listing can be used to demonstrate these two Matcher methods along with providing another example of Matcher.find()./**
* Regular Expression: [$"'\n\d/\\]"
* For Java, must escape the double quote, the \d, and the \\
*/
private final static String REG_EX_COOKBOOK_31_REGEX_STRING = "[$\"'\n\\d/\\\\]";
/**
* Superset String to be used in various Matcher demonstrations, but its key
* differentiating characteristic is that it does NOT begin with a match for
* the regular expression (does not being with $, ", ', new line, numeric
* digit, or backslash).
*/
private final static String SUPERSET_STRING = "regular\\expressions$can_be_2tons\"of'fun.";
/**
* String that should always be match (even exact) for Regular Expressions
* Cookbook Recipe 3.1 regular expression.
*/
private final static String EXACT_MATCH_STRING = "$";
/**
* Superset String set up to start with a match for the Recipe 3.1 regular
* expression pattern from Regular Expressions Cookbook.
*/
private final static String SUPERSET_STRING_STARTING_WITH_MATCH =
EXACT_MATCH_STRING + SUPERSET_STRING;
/**
* Demonstrate Matcher.matches().
*/
private static void demonstrateMatches()
{
final Pattern regExCookbook31Pattern = obtainPatternForRegularExpressionsCookbookRecipe3_1();
final String formatString = "%n%s%s%san EXACT match for regular expression %s";
final Matcher matcher1 = regExCookbook31Pattern.matcher(SUPERSET_STRING);
final boolean exactMatch1 = matcher1.matches();
out.println(
String.format(
formatString,
exactMatch1 ? "YES! " : "NO :( ",
SUPERSET_STRING,
exactMatch1 ? " IS " : " is NOT ",
regExCookbook31Pattern.pattern()));
final Matcher matcher2 = regExCookbook31Pattern.matcher(EXACT_MATCH_STRING);
final boolean exactMatch2 = matcher2.matches();
out.println(
String.format(
formatString,
exactMatch2 ? "YES! " : "NO :( ",
EXACT_MATCH_STRING,
exactMatch2 ? " IS " : " is NOT ",
regExCookbook31Pattern.pattern()));
final Matcher matcher3 = regExCookbook31Pattern.matcher(SUPERSET_STRING_STARTING_WITH_MATCH);
final boolean exactMatch3 = matcher3.matches();
out.println(
String.format(
formatString,
exactMatch3 ? "YES! " : "NO :( ",
SUPERSET_STRING_STARTING_WITH_MATCH,
exactMatch3 ? " IS " : " is NOT ",
regExCookbook31Pattern.pattern()));
}
/**
* Demonstrate Matcher.lookingAt().
*/
private static void demonstrateLookingAt()
{
final Pattern regExCookbook31Pattern = obtainPatternForRegularExpressionsCookbookRecipe3_1();
final String formatString = "%n%s%s%sbegin with a match for regular expression %s";
final Matcher matcher1 = regExCookbook31Pattern.matcher(SUPERSET_STRING);
final boolean portionMatch1 = matcher1.lookingAt();
out.println(
String.format(
formatString,
portionMatch1 ? "YES! " : "NO :( ",
SUPERSET_STRING,
portionMatch1 ? " DOES " : " does NOT ",
regExCookbook31Pattern.pattern()));
final Matcher matcher2 = regExCookbook31Pattern.matcher(EXACT_MATCH_STRING);
final boolean portionMatch2 = matcher2.lookingAt();
out.println(
String.format(
formatString,
portionMatch2 ? "YES! " : "NO :( ",
EXACT_MATCH_STRING,
portionMatch2 ? " DOES " : " does NOT ",
regExCookbook31Pattern.pattern()));
final Matcher matcher3 = regExCookbook31Pattern.matcher(SUPERSET_STRING_STARTING_WITH_MATCH);
final boolean portionMatch3 = matcher3.lookingAt();
out.println(
String.format(
formatString,
portionMatch3 ? "YES! " : "NO :( ",
SUPERSET_STRING_STARTING_WITH_MATCH,
portionMatch3 ? " DOES " : " does NOT ",
regExCookbook31Pattern.pattern()));
}
/**
* Apply Matcher.find() to determine the number of matches in the provided
* sequences to the provided Pattern.
*/
private static void demonstrateFindToCountMatches()
{
final Pattern regExCookbook31Pattern = obtainPatternForRegularExpressionsCookbookRecipe3_1();
final String formatString = "%n%s contains %d matches for regular expression %s";
final Matcher matcher1 = regExCookbook31Pattern.matcher(SUPERSET_STRING);
int numMatches1 = 0;
while (matcher1.find())
{
numMatches1++;
}
out.println(
String.format(
formatString,
SUPERSET_STRING,
numMatches1,
regExCookbook31Pattern.pattern()));
final Matcher matcher2 = regExCookbook31Pattern.matcher(EXACT_MATCH_STRING);
int numMatches2 = 0;
while (matcher2.find())
{
numMatches2++;
}
out.println(
String.format(
formatString,
EXACT_MATCH_STRING,
numMatches2,
regExCookbook31Pattern.pattern()));
final Matcher matcher3 = regExCookbook31Pattern.matcher(SUPERSET_STRING_STARTING_WITH_MATCH);
int numMatches3 = 0;
while (matcher3.find())
{
numMatches3++;
}
out.println(
String.format(
formatString,
SUPERSET_STRING_STARTING_WITH_MATCH,
numMatches3,
regExCookbook31Pattern.pattern()));
}
When the code above is executed (as part of a class and after being invoked), the output appears as shown in the next screen snapshot.

This example confirms what the Javadoc states about the
Matcher.matches() and Matcher.lookingAt() methods. In particular, we see that Matcher.matches() looks for an exact match from the beginning of the provided String against the regular expression while Matcher.lookingAt() only verifies that the provided expression begins with a portion matching the regular expression and does NOT require an exact match. The Matcher.find() method finds and allows action upon any and all matches. The Methods of the Matcher Class portion of the Java Tutorial provides another example of these two methods.Whew! It's been a long way getting here, but I've now covered enough Java handling of regular expressions to move onto what Groovy can do with regular expressions.
I mentioned previously that Groovy doesn't require the developer to explicitly instantiate a Pattern instance to get access to one. Instead this can be done implicitly by prefixing a String with the
~ character. Groovy's goodness doesn't stop there. Groovy also supports "easier" (certainly more concise) syntax for using Java's Matcher. This Groovy syntax is more Perl-like in nature than the Java API counterpart.The Groovy
=~ operator acts something like instantiating Java's Matcher while the ==~ operator acts more like Java's Matcher.matches() (exact match) method. However, it's better than that. The Matcher instance provided by =~ implicitly returns multiple boolean values when used in a conditional statement. Looking at Groovy code makes it more obvious what's happening.NetBeans 6.9 includes Groovy support and it helps us to see that plopping the escape character-ridden Java String used for a regular expression in the Java example above is actually not allowed in Groovy. Here's what NetBeans 6.9 shows for such a case (note the red squiggly line and the error message; thanks NetBeans!).

The small snippet of code shown above in the NetBeans 6.9 editor window indicates that the dollar sign (
$) needs to be escaped in Groovy when specifying the regular expression using double quotes. However, the next line shows that this is not necessary when the "slashy syntax" is used instead of the double quotes. For many developers who use regular expressions, the slashy syntax may be more appealing anyway, but the fact that it doesn't require escaping of $ and the fact that it isn't as confusing when there are double quotes naturally present in the regular expression are sweet morsels.Using the slashy syntax helped avoid the need to escape the
$ or the ", but how does one handle a slash in the regular expression when using slashy syntax? It turns out that NetBeans 6.9 warns us about that.
In response to the NetBeans flagged errors, I can fix the regular expression Pattern definitions to get the following Groovy code that creates Pattern instances with both quoted strings and slashy strings:
#!/usr/bin/env groovy
/*
* Demonstrate how Groovy simplifies regular expression handling.
*/
// Setting up Pattern instances in Groovy
def patternQuoted = ~"[\$\"'\n\\d/\\\\]"
println "It's a Pattern: ${patternQuoted.class} (quoted) for regular expression ${patternQuoted.pattern()}"
def patternSlashy = ~/[$"'\n\d\/\\]/
println "It's a Pattern: ${patternSlashy.class} (slashy) for regular expression ${patternSlashy.pattern()}"
When the above Groovy script is executed, the output looks like that shown in the next screen snapshot.

The snapshot shows the general advantage in presentation of the slashy syntax as compared to the quoted syntax. The slashy syntax required far less escaping than the quoted syntax or the equivalent Java syntax, making the String closer to the original regular expression.
There is one downside evident from this. Note that the new line
\n is left in place as two characters rather than being treated as the new line character in the slashy syntax. This can be addressed by using the syntax ${"\n"} in place of the "\n" in the slashy syntax String as shown next:def patternQuoted = ~"[\$\"'\n\\d/\\\\]"
println "It's a Pattern: ${patternQuoted.class} (quoted) for regular expression ${patternQuoted.pattern()}"
def patternSlashy = ~/[$"'${"\n"}\d\/\\]/
println "It's a Pattern: ${patternSlashy.class} (slashy) for regular expression ${patternSlashy.pattern()}"
Being required to express the newline as
${"\n"} instead of simply "\n" is less than desirable. Fortunately, I don't need a match to a newline for the examples in this post and I generally don't need them in real life use either. Even when I might, I prefer this small price to buy the advantages of the slashy syntax.The next code listing demonstrates Matcher handling in Groovy:
// Setting up Matcher instances in Groovy
def findRegExCookbook31MatchesQuoted = "regular\\expressions\$can_be_2tons\"of'fun." =~ patternQuoted
println "It's a Matcher for Quoted Pattern!: ${findRegExCookbook31MatchesQuoted.class}"
println "\tNumber of matches (count): ${findRegExCookbook31MatchesQuoted.count}"
println "\tNumber of matches (size()): ${findRegExCookbook31MatchesQuoted.size()}"
def findRegExCookbook31MatchesSlashy = "regular\\expressions\$can_be_2tons\"of'fun." =~ patternSlashy
println "It's a Matcher for Slashy Pattern!: ${findRegExCookbook31MatchesQuoted.class}"
println "\tNumber of matches (count): ${findRegExCookbook31MatchesQuoted.count}"
println "\tNumber of matches (size()): ${findRegExCookbook31MatchesQuoted.size()}"
def findRegExCookbook31ExactMatchQuoted = "regular\\expressions\$can_be_2tons\"of'fun." ==~ patternQuoted
println "It's a Boolean for Quoted Pattern!: ${findRegExCookbook31ExactMatchQuoted.class}"
println "\t${findRegExCookbook31ExactMatchQuoted ? 'Exact Match!' : 'NOT Exact Match.'}"
def findRegExCookbook31ExactMatchSlashy = "regular\\expressions\$can_be_2tons\"of'fun." ==~ patternSlashy
println "It's a Boolean for Quoted Pattern!: ${findRegExCookbook31ExactMatchSlashy.class}"
println "\t${findRegExCookbook31ExactMatchSlashy ? 'Exact Match!' : 'NOT Exact Match.'}"
def findRegExCookbook31ExactMatchQuoted2 = '$' ==~ patternQuoted
println "It's a Boolean for Quoted Pattern!: ${findRegExCookbook31ExactMatchQuoted2.class}"
println "\t${findRegExCookbook31ExactMatchQuoted2 ? 'Exact Match!' : 'NOT Exact Match.'}"
def findRegExCookbook31ExactMatchSlashy2 = '$' ==~ patternSlashy
println "It's a Boolean for Quoted Pattern!: ${findRegExCookbook31ExactMatchSlashy2.class}"
println "\t${findRegExCookbook31ExactMatchSlashy2 ? 'Exact Match!' : 'NOT Exact Match.'}"
The output from running this, shown in the next screen snapshot, tells the tale.

This output confirms that the Groovy
=~ operator provides a Matcher instance that is smarter than your average Matcher. That's because the Groovy Matcher (part of Groovy GDK) provides many additional utility methods including two used in the code above (getCount() used as count property and size() method). The GDK's Matcher.asBoolean() method is behind the magic that allows a Groovy Matcher to return a boolean in a conditional expression. I don't discuss it here, but the GDK does provide one small extension to the Pattern class as well.Mr. Haki provides a nice overview of Groovy's treatment of regular expressions via Matchers in his post Groovy Goodness: Matchers for Regular Expressions. He similarly covers Groovy handling of Patterns in the post Groovy Goodness: Using Regular Expression Pattern Class.
Conclusion
The ability to use more natural-looking (at least by regular expressions standards) regular expressions, the ability to use operators rather than APIs and method calls, and the extra "smarts" added to GDK's extensions of the Java RegEx library make using regular expressions in Groovy easier and more natural to the people who are probably most familiar with regular expressions: script writers. As is true with most of Groovy, Groovy's regular expression support is a reflection of Java's regular expression support. Generally speaking, anything one knows about regular expressions in Java (including the syntax supported in Java's flavor/dialect) can be applied when using regular expressions in Groovy. In several cases, though, Grooy makes it easier to use. With anything, but especially with regular expressions, easier is always better.
Additional Resources
I mentioned previously that there are numerous great online resources on Groovy's support for regular expressions. Some of them are listed here. I especially recommend the first listed resource (Groovy: Don't Fear the RegExp) and book I frequently cited in this post (Regular Expressions Cookbook).
⇒ Regular Expressions Cookbook
⇒ Groovy: Don’t Fear the RegExp
⇒ Groovy Regular Expressions
⇒ Groovy Tutorial 4 - Groovy Regular Expressions Basics
⇒ Groovy Goodness: Using Regular Expression Pattern Class
⇒ Groovy Goodness: Matchers for Regular Expressions
⇒ Big Collection of Regular Expressions (not specific to Groovy)
⇒ Finding Files by Name with Groovy
⇒ Online Regular Expression Test Page (uses java.util.regex)
⇒ RegexBuddy
⇒ RegexPal
⇒ Regular Expression Tool
Tuesday, December 28, 2010
Significant Software Development Developments of 2010
With the end of 2010 rapidly approaching, it is time to summarize what I believe are the ten most significant developments in 2010 in the software development community. As I have disclaimed before, this is entirely biased toward my interests. It is difficult to gauge the importance of events in spaces one is not familiar with, so I tend to favor areas that I do know and am able to make some educated (albeit anecdotal) conclusions about their significance. I started writing this blog in late 2007 and have written posts similar to this one on significant software development developments for the years 2007, 2008, and 2009.
Although I enjoy many different programming languages, I would most closely associate myself with Java programming. Therefore, it's not surprising that this year's developments are dominated by Oracle's ownership and stewardship of Java. It is a challenge to decide whether to represent all of these things under one item, to have an item for each issue, or to go somewhere between. I chose the last option and bundle multiple items related to Oracle's stewardship of Java into a smaller number of groups, but do not limit all of these events to one of the items.
The interesting thing is that even with only 3 days left in the year 2010, there is still the possibility that a major development could occur that should make this list.
10. Java EE 6
Java EE 6 was technically finalized in late 2009, but 2010 has been its year of implementation and adoption. There has been significant enthusiasm and evangelism for Java EE 6 this year. Cameron McKenzie's Moving from Spring to Java EE 6: The Age of Frameworks is Over generated significant community discussion. There is much to like about Java EE 6. Even Java EE 5 (and more specifically EJB3) had made enterprise Java development less difficult so that developers were more likely to actually return to use of Java EE. The question is whether Java EE 6 can lure even more developers away from the Spring Framework and other common alternatives.
9. .NET Framework 4 and Visual Studio 2010
Roughly 2 1/2 years after the release of .NET 3.5 and Visual Studio 2008, .NET 4 and Visual Studio 2010 were released in April of 2010. .NET Framework 4 offers numerous new features including support for covariance and contravariance for generics, simpler property syntax in VB.NET, optional method parameters in C#, late/dynamic binding in C#, security improvements, improved ability to measure performance diagnostics, background garbage collection as a replacement for concurrent garbage collection, code contracts, and built-in Tuple support.
Visual Studio 2010 includes support for F# (functional programming) and many other improvements.
8. OpenJDK: More Community-Based Than Ever
For years, Java developers worldwide and organizations associated with Java (IBM) clamored for Sun Microsystems to open source Java. Even when Sun did open source Java, not everyone was pleased. Different organizations lined up behind the two favorites for an open source Java implementation: Sun's OpenJDK and Apache Harmony. The Oracle acquisition of Sun has now appeared to turn the tide definitively in OpenJDK's favor with Apple now supporting OpenJDK and IBM now supporting OpenJDK. IBM had been the big corporate sponsor associated with Apache Harmony, so the shift of IBM to be aligned with OpenJDK is a huge boon for OpenJDK at a large cost to Apache Harmony. With major vendors IBM, Apple, and Oracle all behind OpenJDK, that open source Java implementation seems to definitely have a stranglehold on one of the most important pieces of many successful open source projects: strong financial backing from project sponsors. Because these vendors have much influence with developers, it also plays well into another important aspect of successful open source projects: large communities are advantageous.
7. Oracle/Google Dispute over Android
For those of us who identify ourselves as members of the Java community, this Oracle lawsuit over Android and Java is a big deal because one of the attractive aspects of Android development is the ability to use language syntax we are familiar with to develop applications for a rapidly growing number of mobile devices that run on the Android platform. This lawsuit also has the attention of open source enthusiasts and Google has attempted to frame the lawsuit as a "lawsuit against open source." Even for those who are not interested in Java or open source, this is a big development because it affects the mobile development community and because it may establish or reinforce precedents in areas of patent law and other intellectual property legal affairs. I'm no attorney and cannot comment on any of that with any type of knowledge, but it seems that the ramifications of this are potentially huge. For Java developers, there is also a question of fragmentation, though the association of IBM and Apple with OpenJDK seems to mitigate that concern to some extent. That being stated, Google's boycott of JavaOne 2010 due to the lawsuit is an example of how the lawsuit and the response to the lawsuit have already negatively impacted the Java community. I think it's worth noting that Sun also did not like Google's handling of Android, but chose to just "grin and bear it" (my summary).
6. The Rise of HTML5
I have been frustrated with HTML/CSS/DOM/JavaScript idiosyncrasies across major web browers (particularly the most popular web browser) for years. I'll admit to some skepticism regarding adoption of HTML5 at a level that would make it truly viable. Although it's certainly "not there yet," HTML5 finally seems to be gaining the traction it needs among the major browsers and among web developers and authors to be worth paying attention to. In particular, market-leading browsers Google Chrome, Firefox 4 (beta), and Microsoft Internet Explorer 9 (beta) have or are advertised to have significant greater HTML5 support.
As important as it is that the desktop web browsers provide consistent HTML5 support to make it more attractive to use, it seems that the mobile device arena is already pushing HTML5 features heavily. Many of the HTML5 features, such as the web forms features, are more useful and more interesting on mobile device browsers where the savings to the user provide by the new, more granular HTML forms controls are truly appreciable.
5. Mobile Device Development
Although desktop and enterprise applications have lost some of their luster in the blogosphere in recent years as web development has seemed to dominate the blogosphere, the desktop web browser development appears to be now losing some of those gains to mobile device development. Mobile devices are becoming increasingly prevalent. Although many software developers have never needed to learn web development skills to do their enterprise or desktop jobs and although many web developers have never needed to learn desktop skills or enterprise skills to do their jobs, I believe that developers who gain at least some basic mobile device development skills will be better positioned for future work.
See Biggest Mobile Stories of 2010 for more specifics on the biggest mobile developments of 2010. Jason Hiner has called 2010 "the year of the smartphone."
4. New Direction for Java: Java 7 and Java 8
Sun allowed the Java programming language to languish for years. Shortly before JavaOne 2010, however, it was announced that there were two competing plans for the future of Java. By JavaOne 2010, it was known and announced that Plan B would be implemented. This plan focuses on an earlier delivery of Java 7 with fewer features than would be possible for a more complete delivery. The missing features would come relatively quickly afterward in Java 8. Since that time, there's been significant blogosphere and other online coverage of the features expected to be delivered with Java 7. I also thought that some of the ideas put out there at JavaOne 2010 for post-Java 8 are promising. I personally would love to see reified generics. Mark Reinhold announced Plans A and B and the decision to move forward with Plan B, so it was not surprising when he blogged on the release of the four Java Specification Requests related to the forthcoming new versions of Java: JSR 334, JSR 335, JSR 336, and JSR 337.
3. Oracle Closes Deal for Sun
Given that several of the items above are somewhat related to Oracle's acquisition of Sun and given that the (at the time) pending acquisition was a big deal (my #1) in 2009, it is not surprising that the actual close of the deal is considered a major software development event in 2010. I covered this event in greater detail in the blog post Oracle/Sun: The Deal Has Closed. Had I included all of the effects of this acquisition described above into a single item, that single item would have been #1 again this year.
2. Increasing Popularity of Groovy and Scala and Alternative JVM Languages
One of my observations from JavaOne 2010 is that Groovy is close to being considered "assumed knowledge" in the Java community. Numerous presenters discussed and/or used Groovy to facilitate their examples, even when the presentation was not explicitly focused on Groovy. Although presenters still usually asked who was familiar with Groovy, most audience participants raised their hands in the affirmative and most presenters did not spend much time on Groovy basics unless in a Groovy-focused presentation. I have always considered it a sign that something is an "assumed knowledge" when the presenters stop asking who knows it before using it. For example, I remember when, years ago, presenters asked if audience members knew XML or Ant. They don't ask about those two anymore and I don't think it will be long before they don't ask regarding Groovy either.
Scala seems to have arrived where Groovy was not so long ago: many Java developers have heard of it, but relatively few have actually tried it out. One person at JavaOne 2010 who seemed to know what he was talking about when it comes to Scala described Scala as a language that might not be the best at any one thing, but is second best at nearly everything. I have not felt a driving need to learn more about Scala, but I do pay attention to its acceptance and adoption rate in case I decide I need to invest more time in it.
Clojure also seems to be separating itself from other JVM alternative languages, but seems a little behind Groovy and Scala at this point in terms of developer interest and evangelism.
Alternative languages on the JVM continues to be a strong trend and I think Oracle's JavaFX plans (discussed above) make a lot of sense given that developers will more readily be able to apply their favorite JVM language to working with JavaFX in the future.
1. Cloud Computing
I'll admit that I still have some lingering doubts about cloud computing as a long-term widely applicable concept. I still question whether it's something a majority of developers will ever really need to deal with as-is, but at this point it's obvious that at least some significant portion of developers will and already are dealing with development for the cloud. When all the major vendors want a piece of the action, there's at least short-term gains associated with that action. IBM, Oracle, and Microsoft have all expressed commitment to cloud computing. Although it's normal for vendors to chase anything new because it's easier to sell products and services for new rather than for familiar, getting all the vendors behind something means that we're going to get it advertised to us relentlessly whether we want it or not. That type of sales pressure often leads to acceptance.
Despite my personal misgivings about cloud computing, I realize that it is widely discussed and covered in development circles. At the very least, cloud computing is the "flavor of the month" (or few years), but it has the potential to be more than that. Like many things, cloud computing has its place and situations it fits nicely. But, as is also the case with just about anything, cloud computing is not going to be the appropriate solution for all customers in all situations.
See Top 10 Cloud Stories of 2010 for more a significantly more detailed explanation of some of the year's biggest stories in cloud computing.
Honorable Mention
The "Honorable Mention" section of this post covers items that did not make my Top Ten, but are nonetheless significant developments in software development.
JavaFX May Have Life After All, But JavaFX Script is Dead
One of the largest announcements out of JavaOne 2010 was the new direction for JavaFX. I never could understand Sun's seemingly arrogant insistence on coercing developers to learn a new language and use a technology that was largely slideware for a couple of JavaOne conferences before being truly viable. Most developers I know who wanted a "Java solution" instead of Flex or something else wanted it so they could use the Java they already knew. Although JavaFX did make use of the JVM, it was not particularly friendly to incorporation with Java or the other JVM-based languages such as Groovy (though it has been possible as evidenced by Steve Chin's presentation JavaFX 2.0 with Alternative Languages and Visage). Oracle showed insight into what developers really want and need and a desire to meet that need with their announcement of plans for JavaFX to support Java API calls that will make JavaFX more attractive for use with languages such as Java, Groovy, Scala, Clojure, and on and on. I had pretty much written off JavaFX before JavaOne 2010, but Oracle may be able to save it if they can deliver on their intentions and advertised plan. Although I don't miss JavaFX Script, those who do will likely find Visage (open source project based on JavaFX Script compiler) interesting.
Flash on Mobile Devices
For some, the advent of Flash on many mobile devices is unwelcome news. However, I know several iPhone users who are tired of being shut-out from Flash-based applications. It seems that lack of Flash and the lack of carrier options (AT&T is the exclusive carrier) are two of the most common complaints I hear from iPhone users.
NoSQL
The concept of the NoSQL database became even more popular in 2010. Not everyone is caught up in the NoSQL hype. I am trying to decide whether NoSQL will make long-lasting real inroads against the relational database or if it's going to be another in a long line of "also rans" such as the object-oriented databases and XML databases of past years. At the very least, NoSQL approaches probably will at least maintain some support (just as there are still OO and native XML databases available). The question is whether they can garner significant market share from the relational databases. In NoSQL is Software Darwinism, Jeremy Zawodny summarizes where I think NoSQL is headed: NoSQL implementations will be part of the landscape, but relational databases will still be prevalent.
Objective-C
Obviously riding on the back of the iPhone, Objective-C enjoyed a tremendous adoption rate in 2010 as evidenced by the Tiobe chart for Objective-C. Although the Tiobe index is not (and does not claim to be) a perfect gauge of a language's popularity, it does indicate what developers are searching for on the web with popular search engines. According to the December index, Objective-C is the leading candidate for the Programming Language Hall of Fame, which is "given to the programming language that has the highest rise in ratings in a year." Only Python (the 2007 winner) appears to have a chance to win that award over Objective-C in 2010.
Software Development Blogging
Software development blogging itself had an interesting year in 2010. One of the leading software development bloggers, Joel Spolsky, announced that he'd no longer blog like he used to in the column Let's Take This Offline. His blog, Joel on Software, is still online, but the content is dramatically different now. Bruce Eckel has not given up writing software development blogs entirely, but announced his intention to focus "from software development to business." This is pretty big news from the author of Thinking in Java, Thinking in C++, and the well-read Hybridizing Java article.
Since May 2009, it has sounded like another well-known software development blogger, Steve Yegge, was getting ready to stop writing blogs ("We're getting close to the end of my blog. After today's entry, I only have three left to write. After that, I'll only blog anonymously or (more likely) not at all."). He has written three since, but certainly doesn't write them as frequently as he used to and mentions a "nice relaxing blog-free year" in one of them. Although the number/frequency is down, the last two (of three written in 2010) are funny.
The blogosphere is littered with blogs that were started with ambitious plans, had one or two posts written, and then were indefinitely abandoned. What makes the recent announcements from Joel Spolsky, Bruce Eckel, and Steve Yegge more significant is that these were regularly, prolific bloggers with large readerships who have either stopped writing technical software blogs altogether or have significantly scaled back their investment of time and energy in doing so.
Writing and maintaining a blog can be difficult work that requires a significant time investment. If I had not attended JavaOne 2010 this year on a Blogger Pass, it is likely that my own blog would have had fewer posts for the 12 months of 2010 than over any other twelve month period. It can be difficult to come up with enough ideas that seem useful to blog on and then can be time-consuming to write about those ideas. That being stated, I still believe that we'd all benefit from more software developers writing blogs.
Although software development-related blogging may have reached its zenith, I don't think it is going away altogether anytime soon. Java.net editor Kevin Farnham's observation that conference blogging has returned (after an apparently temporary replacement by Tweets or so-called microblogging) is evidence that software development blogging is still active and useful.
Java Community Process in Danger
There is an unsurprising dispute between the Apache Software Foundation and Oracle over Java licensing and control. I think most of us in the Java community would like to see these issues worked out, but only the revisionist historians among us think this is all Oracle: Apache had disagreements about this with Sun as well. Now, the Apache Software Foundation has resigned from the Executive Committee of the Java Community Process. Others to have resigned recently from the JCP include Doug Lea and Tim Peierls. The JCP was under stress even before Oracle's acquisition of Sun. Now, many prominent folks in the Java development community are asking, Is the JCP Dead?
Lucene
Apache Lucene has been around for more than a decade, but 2010 was certainly a big year for Lucene. Many Java developers that I know started to get serious about Lucene in 2010 and its adoption rate certainly seems to have taken off. Grant Ingersoll provides a much more descriptive overview of Lucene in 2010 in the post The Apache Lucene Ecosystem: My View of 2010. Ingersoll highlights the merger of Lucene and Solr as well as additions and enhancements to Lucene and Solr to support trendy topics in software development such as cloud computing and location-aware applications. He also points out that Twitter used Lucene in its search engine in 2010.
iBATIS Forks/Moves from ASF to Google Code and Becomes MyBatis
In 2010, iBATIS creator Clinton Begin and the rest of the iBATIS for Java and iBATIS.net committers made the decision to move their efforts from iBATIS under the Apache Software Foundation umbrella to Google Code. They did this by forking iBATIS and calling it MyBatis (somewhat reminiscent of MySQL naming?) on Google Code. As Begin points out in the 21 May 2010 entry on the main page of ASF iBATIS project, very little that matters to developers changes immediately. An important consistency is that MyBatis retains the Apache License, Version 2.0 that its source iBATIS was licensed under.
I have not used iBATIS (or MyBatis), but I have heard and read many good things about it. I found this development particularly interesting from the perspective of wondering why the project committers are moving the project from the deservedly venerated ASF to Google Code. The explanations for this transition can be found in at least two primary sources.
In the About MyBatis page, there is a section called "The Apache Software Foundation" that contains an informative paragraph:
Some implications of the motivations for the change can be derived from the above paragraph, but it even more details and clarity are found on the iBATIS home page that now focuses on the move to MyBatis on Google Code. I think the section under the heading "GOALS" is particularly informative in terms of understanding the reason for the transition:
The Wiki page DocIbatis2MyBatis discusses how to migrate from iBATIS 3 to MyBatis and includes an interesting twist on copyright versus license as a response to the question "Did the license change?": "The copyright for future code will change. But the license is still the Apache License 2.0."
With the "direct fork" of iBATIS to MyBatis, ASF iBATIS has now been moved into the Apache Attic with other Apache Software Foundation products that have similarly met their end of life such as Beehive, Crimson (replaced by Xerces), and Shale.
Conclusion
As is the case every year, I found it difficult to limit my list to ten items. There is no doubt that others would place other developments in the top ten, but I believe that this list of developments is a good starting point for reviewing what's happened in the world of software development (especially in Java development) in 2010.
Additional Reading
This is the time of year for this type of blog posts. Others that may be of interest include The Top 7 Java Stories of 2010, Top 10 Software Stories of 2010, The Top Tech Tech Stories of 2010, 2010: Yet Another Great Year for PHP, Top 12 Tech Embarrassments of 2010, and The Major Incidents on the Internet in 2010.
Although I enjoy many different programming languages, I would most closely associate myself with Java programming. Therefore, it's not surprising that this year's developments are dominated by Oracle's ownership and stewardship of Java. It is a challenge to decide whether to represent all of these things under one item, to have an item for each issue, or to go somewhere between. I chose the last option and bundle multiple items related to Oracle's stewardship of Java into a smaller number of groups, but do not limit all of these events to one of the items.
The interesting thing is that even with only 3 days left in the year 2010, there is still the possibility that a major development could occur that should make this list.
10. Java EE 6
Java EE 6 was technically finalized in late 2009, but 2010 has been its year of implementation and adoption. There has been significant enthusiasm and evangelism for Java EE 6 this year. Cameron McKenzie's Moving from Spring to Java EE 6: The Age of Frameworks is Over generated significant community discussion. There is much to like about Java EE 6. Even Java EE 5 (and more specifically EJB3) had made enterprise Java development less difficult so that developers were more likely to actually return to use of Java EE. The question is whether Java EE 6 can lure even more developers away from the Spring Framework and other common alternatives.
9. .NET Framework 4 and Visual Studio 2010
Roughly 2 1/2 years after the release of .NET 3.5 and Visual Studio 2008, .NET 4 and Visual Studio 2010 were released in April of 2010. .NET Framework 4 offers numerous new features including support for covariance and contravariance for generics, simpler property syntax in VB.NET, optional method parameters in C#, late/dynamic binding in C#, security improvements, improved ability to measure performance diagnostics, background garbage collection as a replacement for concurrent garbage collection, code contracts, and built-in Tuple support.
Visual Studio 2010 includes support for F# (functional programming) and many other improvements.
8. OpenJDK: More Community-Based Than Ever
For years, Java developers worldwide and organizations associated with Java (IBM) clamored for Sun Microsystems to open source Java. Even when Sun did open source Java, not everyone was pleased. Different organizations lined up behind the two favorites for an open source Java implementation: Sun's OpenJDK and Apache Harmony. The Oracle acquisition of Sun has now appeared to turn the tide definitively in OpenJDK's favor with Apple now supporting OpenJDK and IBM now supporting OpenJDK. IBM had been the big corporate sponsor associated with Apache Harmony, so the shift of IBM to be aligned with OpenJDK is a huge boon for OpenJDK at a large cost to Apache Harmony. With major vendors IBM, Apple, and Oracle all behind OpenJDK, that open source Java implementation seems to definitely have a stranglehold on one of the most important pieces of many successful open source projects: strong financial backing from project sponsors. Because these vendors have much influence with developers, it also plays well into another important aspect of successful open source projects: large communities are advantageous.
7. Oracle/Google Dispute over Android
For those of us who identify ourselves as members of the Java community, this Oracle lawsuit over Android and Java is a big deal because one of the attractive aspects of Android development is the ability to use language syntax we are familiar with to develop applications for a rapidly growing number of mobile devices that run on the Android platform. This lawsuit also has the attention of open source enthusiasts and Google has attempted to frame the lawsuit as a "lawsuit against open source." Even for those who are not interested in Java or open source, this is a big development because it affects the mobile development community and because it may establish or reinforce precedents in areas of patent law and other intellectual property legal affairs. I'm no attorney and cannot comment on any of that with any type of knowledge, but it seems that the ramifications of this are potentially huge. For Java developers, there is also a question of fragmentation, though the association of IBM and Apple with OpenJDK seems to mitigate that concern to some extent. That being stated, Google's boycott of JavaOne 2010 due to the lawsuit is an example of how the lawsuit and the response to the lawsuit have already negatively impacted the Java community. I think it's worth noting that Sun also did not like Google's handling of Android, but chose to just "grin and bear it" (my summary).
6. The Rise of HTML5
I have been frustrated with HTML/CSS/DOM/JavaScript idiosyncrasies across major web browers (particularly the most popular web browser) for years. I'll admit to some skepticism regarding adoption of HTML5 at a level that would make it truly viable. Although it's certainly "not there yet," HTML5 finally seems to be gaining the traction it needs among the major browsers and among web developers and authors to be worth paying attention to. In particular, market-leading browsers Google Chrome, Firefox 4 (beta), and Microsoft Internet Explorer 9 (beta) have or are advertised to have significant greater HTML5 support.
As important as it is that the desktop web browsers provide consistent HTML5 support to make it more attractive to use, it seems that the mobile device arena is already pushing HTML5 features heavily. Many of the HTML5 features, such as the web forms features, are more useful and more interesting on mobile device browsers where the savings to the user provide by the new, more granular HTML forms controls are truly appreciable.
5. Mobile Device Development
Although desktop and enterprise applications have lost some of their luster in the blogosphere in recent years as web development has seemed to dominate the blogosphere, the desktop web browser development appears to be now losing some of those gains to mobile device development. Mobile devices are becoming increasingly prevalent. Although many software developers have never needed to learn web development skills to do their enterprise or desktop jobs and although many web developers have never needed to learn desktop skills or enterprise skills to do their jobs, I believe that developers who gain at least some basic mobile device development skills will be better positioned for future work.
See Biggest Mobile Stories of 2010 for more specifics on the biggest mobile developments of 2010. Jason Hiner has called 2010 "the year of the smartphone."
4. New Direction for Java: Java 7 and Java 8
Sun allowed the Java programming language to languish for years. Shortly before JavaOne 2010, however, it was announced that there were two competing plans for the future of Java. By JavaOne 2010, it was known and announced that Plan B would be implemented. This plan focuses on an earlier delivery of Java 7 with fewer features than would be possible for a more complete delivery. The missing features would come relatively quickly afterward in Java 8. Since that time, there's been significant blogosphere and other online coverage of the features expected to be delivered with Java 7. I also thought that some of the ideas put out there at JavaOne 2010 for post-Java 8 are promising. I personally would love to see reified generics. Mark Reinhold announced Plans A and B and the decision to move forward with Plan B, so it was not surprising when he blogged on the release of the four Java Specification Requests related to the forthcoming new versions of Java: JSR 334, JSR 335, JSR 336, and JSR 337.
3. Oracle Closes Deal for Sun
Given that several of the items above are somewhat related to Oracle's acquisition of Sun and given that the (at the time) pending acquisition was a big deal (my #1) in 2009, it is not surprising that the actual close of the deal is considered a major software development event in 2010. I covered this event in greater detail in the blog post Oracle/Sun: The Deal Has Closed. Had I included all of the effects of this acquisition described above into a single item, that single item would have been #1 again this year.
2. Increasing Popularity of Groovy and Scala and Alternative JVM Languages
One of my observations from JavaOne 2010 is that Groovy is close to being considered "assumed knowledge" in the Java community. Numerous presenters discussed and/or used Groovy to facilitate their examples, even when the presentation was not explicitly focused on Groovy. Although presenters still usually asked who was familiar with Groovy, most audience participants raised their hands in the affirmative and most presenters did not spend much time on Groovy basics unless in a Groovy-focused presentation. I have always considered it a sign that something is an "assumed knowledge" when the presenters stop asking who knows it before using it. For example, I remember when, years ago, presenters asked if audience members knew XML or Ant. They don't ask about those two anymore and I don't think it will be long before they don't ask regarding Groovy either.
Scala seems to have arrived where Groovy was not so long ago: many Java developers have heard of it, but relatively few have actually tried it out. One person at JavaOne 2010 who seemed to know what he was talking about when it comes to Scala described Scala as a language that might not be the best at any one thing, but is second best at nearly everything. I have not felt a driving need to learn more about Scala, but I do pay attention to its acceptance and adoption rate in case I decide I need to invest more time in it.
Clojure also seems to be separating itself from other JVM alternative languages, but seems a little behind Groovy and Scala at this point in terms of developer interest and evangelism.
Alternative languages on the JVM continues to be a strong trend and I think Oracle's JavaFX plans (discussed above) make a lot of sense given that developers will more readily be able to apply their favorite JVM language to working with JavaFX in the future.
1. Cloud Computing
I'll admit that I still have some lingering doubts about cloud computing as a long-term widely applicable concept. I still question whether it's something a majority of developers will ever really need to deal with as-is, but at this point it's obvious that at least some significant portion of developers will and already are dealing with development for the cloud. When all the major vendors want a piece of the action, there's at least short-term gains associated with that action. IBM, Oracle, and Microsoft have all expressed commitment to cloud computing. Although it's normal for vendors to chase anything new because it's easier to sell products and services for new rather than for familiar, getting all the vendors behind something means that we're going to get it advertised to us relentlessly whether we want it or not. That type of sales pressure often leads to acceptance.
Despite my personal misgivings about cloud computing, I realize that it is widely discussed and covered in development circles. At the very least, cloud computing is the "flavor of the month" (or few years), but it has the potential to be more than that. Like many things, cloud computing has its place and situations it fits nicely. But, as is also the case with just about anything, cloud computing is not going to be the appropriate solution for all customers in all situations.
See Top 10 Cloud Stories of 2010 for more a significantly more detailed explanation of some of the year's biggest stories in cloud computing.
Honorable Mention
The "Honorable Mention" section of this post covers items that did not make my Top Ten, but are nonetheless significant developments in software development.
JavaFX May Have Life After All, But JavaFX Script is Dead
One of the largest announcements out of JavaOne 2010 was the new direction for JavaFX. I never could understand Sun's seemingly arrogant insistence on coercing developers to learn a new language and use a technology that was largely slideware for a couple of JavaOne conferences before being truly viable. Most developers I know who wanted a "Java solution" instead of Flex or something else wanted it so they could use the Java they already knew. Although JavaFX did make use of the JVM, it was not particularly friendly to incorporation with Java or the other JVM-based languages such as Groovy (though it has been possible as evidenced by Steve Chin's presentation JavaFX 2.0 with Alternative Languages and Visage). Oracle showed insight into what developers really want and need and a desire to meet that need with their announcement of plans for JavaFX to support Java API calls that will make JavaFX more attractive for use with languages such as Java, Groovy, Scala, Clojure, and on and on. I had pretty much written off JavaFX before JavaOne 2010, but Oracle may be able to save it if they can deliver on their intentions and advertised plan. Although I don't miss JavaFX Script, those who do will likely find Visage (open source project based on JavaFX Script compiler) interesting.
Flash on Mobile Devices
For some, the advent of Flash on many mobile devices is unwelcome news. However, I know several iPhone users who are tired of being shut-out from Flash-based applications. It seems that lack of Flash and the lack of carrier options (AT&T is the exclusive carrier) are two of the most common complaints I hear from iPhone users.
NoSQL
The concept of the NoSQL database became even more popular in 2010. Not everyone is caught up in the NoSQL hype. I am trying to decide whether NoSQL will make long-lasting real inroads against the relational database or if it's going to be another in a long line of "also rans" such as the object-oriented databases and XML databases of past years. At the very least, NoSQL approaches probably will at least maintain some support (just as there are still OO and native XML databases available). The question is whether they can garner significant market share from the relational databases. In NoSQL is Software Darwinism, Jeremy Zawodny summarizes where I think NoSQL is headed: NoSQL implementations will be part of the landscape, but relational databases will still be prevalent.
Objective-C
Obviously riding on the back of the iPhone, Objective-C enjoyed a tremendous adoption rate in 2010 as evidenced by the Tiobe chart for Objective-C. Although the Tiobe index is not (and does not claim to be) a perfect gauge of a language's popularity, it does indicate what developers are searching for on the web with popular search engines. According to the December index, Objective-C is the leading candidate for the Programming Language Hall of Fame, which is "given to the programming language that has the highest rise in ratings in a year." Only Python (the 2007 winner) appears to have a chance to win that award over Objective-C in 2010.
Software Development Blogging
Software development blogging itself had an interesting year in 2010. One of the leading software development bloggers, Joel Spolsky, announced that he'd no longer blog like he used to in the column Let's Take This Offline. His blog, Joel on Software, is still online, but the content is dramatically different now. Bruce Eckel has not given up writing software development blogs entirely, but announced his intention to focus "from software development to business." This is pretty big news from the author of Thinking in Java, Thinking in C++, and the well-read Hybridizing Java article.
Since May 2009, it has sounded like another well-known software development blogger, Steve Yegge, was getting ready to stop writing blogs ("We're getting close to the end of my blog. After today's entry, I only have three left to write. After that, I'll only blog anonymously or (more likely) not at all."). He has written three since, but certainly doesn't write them as frequently as he used to and mentions a "nice relaxing blog-free year" in one of them. Although the number/frequency is down, the last two (of three written in 2010) are funny.
The blogosphere is littered with blogs that were started with ambitious plans, had one or two posts written, and then were indefinitely abandoned. What makes the recent announcements from Joel Spolsky, Bruce Eckel, and Steve Yegge more significant is that these were regularly, prolific bloggers with large readerships who have either stopped writing technical software blogs altogether or have significantly scaled back their investment of time and energy in doing so.
Writing and maintaining a blog can be difficult work that requires a significant time investment. If I had not attended JavaOne 2010 this year on a Blogger Pass, it is likely that my own blog would have had fewer posts for the 12 months of 2010 than over any other twelve month period. It can be difficult to come up with enough ideas that seem useful to blog on and then can be time-consuming to write about those ideas. That being stated, I still believe that we'd all benefit from more software developers writing blogs.
Although software development-related blogging may have reached its zenith, I don't think it is going away altogether anytime soon. Java.net editor Kevin Farnham's observation that conference blogging has returned (after an apparently temporary replacement by Tweets or so-called microblogging) is evidence that software development blogging is still active and useful.
Java Community Process in Danger
There is an unsurprising dispute between the Apache Software Foundation and Oracle over Java licensing and control. I think most of us in the Java community would like to see these issues worked out, but only the revisionist historians among us think this is all Oracle: Apache had disagreements about this with Sun as well. Now, the Apache Software Foundation has resigned from the Executive Committee of the Java Community Process. Others to have resigned recently from the JCP include Doug Lea and Tim Peierls. The JCP was under stress even before Oracle's acquisition of Sun. Now, many prominent folks in the Java development community are asking, Is the JCP Dead?
Lucene
Apache Lucene has been around for more than a decade, but 2010 was certainly a big year for Lucene. Many Java developers that I know started to get serious about Lucene in 2010 and its adoption rate certainly seems to have taken off. Grant Ingersoll provides a much more descriptive overview of Lucene in 2010 in the post The Apache Lucene Ecosystem: My View of 2010. Ingersoll highlights the merger of Lucene and Solr as well as additions and enhancements to Lucene and Solr to support trendy topics in software development such as cloud computing and location-aware applications. He also points out that Twitter used Lucene in its search engine in 2010.
iBATIS Forks/Moves from ASF to Google Code and Becomes MyBatis
In 2010, iBATIS creator Clinton Begin and the rest of the iBATIS for Java and iBATIS.net committers made the decision to move their efforts from iBATIS under the Apache Software Foundation umbrella to Google Code. They did this by forking iBATIS and calling it MyBatis (somewhat reminiscent of MySQL naming?) on Google Code. As Begin points out in the 21 May 2010 entry on the main page of ASF iBATIS project, very little that matters to developers changes immediately. An important consistency is that MyBatis retains the Apache License, Version 2.0 that its source iBATIS was licensed under.
I have not used iBATIS (or MyBatis), but I have heard and read many good things about it. I found this development particularly interesting from the perspective of wondering why the project committers are moving the project from the deservedly venerated ASF to Google Code. The explanations for this transition can be found in at least two primary sources.
In the About MyBatis page, there is a section called "The Apache Software Foundation" that contains an informative paragraph:
In six years [since Begin's donation of iBATIS name and code to ASF in 2004] a lot had changed in the world of open source software. Everything from development practices, infrastructure, licensing and even database technology changed drastically. In 2010 the core development team decided that these developments were worth exploring and that iBATIS would benefit from some significant changes. This was a serious consideration and the move meant leaving the iBATIS name behind.
Some implications of the motivations for the change can be derived from the above paragraph, but it even more details and clarity are found on the iBATIS home page that now focuses on the move to MyBatis on Google Code. I think the section under the heading "GOALS" is particularly informative in terms of understanding the reason for the transition:
We believe can improve a number of things by making this move, including (but not limited to):
* Lighter process
* More frequent releases
* Unified infrastructure
* Modernized tools (source control etc.)
* Build and deployment automation
* Easier to use mailing lists
* Single sign-on for users
* Greater community involvement
* More productive development team
The Wiki page DocIbatis2MyBatis discusses how to migrate from iBATIS 3 to MyBatis and includes an interesting twist on copyright versus license as a response to the question "Did the license change?": "The copyright for future code will change. But the license is still the Apache License 2.0."
With the "direct fork" of iBATIS to MyBatis, ASF iBATIS has now been moved into the Apache Attic with other Apache Software Foundation products that have similarly met their end of life such as Beehive, Crimson (replaced by Xerces), and Shale.
Conclusion
As is the case every year, I found it difficult to limit my list to ten items. There is no doubt that others would place other developments in the top ten, but I believe that this list of developments is a good starting point for reviewing what's happened in the world of software development (especially in Java development) in 2010.
Additional Reading
This is the time of year for this type of blog posts. Others that may be of interest include The Top 7 Java Stories of 2010, Top 10 Software Stories of 2010, The Top Tech Tech Stories of 2010, 2010: Yet Another Great Year for PHP, Top 12 Tech Embarrassments of 2010, and The Major Incidents on the Internet in 2010.
Monday, December 27, 2010
The Best Decisions are Those We Must Live With
We have all been the victims of others' poor decisions. This is especially painful when we, and not those making the decisions, are the victims. I have seen many times in my career when a particularly bad idea was implemented because the person making the decision had no relevant experience to understand the consequences of his or her decision. These same people often don't have to implement the poor decision and therefore don't learn from their mistakes. In this post, I look at ways to reduce or avoid this effect.
Most decision-makers (managers, leads, customers) want to succeed and are trying to make good decisions. The problem is that they may lack a full understanding of the total costs, the risks. and the unintended consequences of a particular decision. It it sometimes sufficient to point out the total costs, the risks and the potential unintended consequences of the decision to head the poor decision off. Unfortunately, expressed risks, costs, and unintended consequences are often dismissed as overstated or not likely to be incurred.
In the remainder of this post, I look at steps that can be taken to attempt to stop or reduce poor decisions from having long-term adverse negative impacts on success.
Help or Allow the Decision Maker to Taste the Idea
A group of fellow developers and I stopped a particularly bad idea from being implemented when we helped the management team making the decision to visualize the true costs (time and schedule) of the decision. As they envisioned themselves implementing this onerous approach, they realized what we had been trying to tell them: their idea sounded good at first, but was very inefficient when considering the realities of the tools we had at the time. Only when they pictured themselves waiting on this tool to run did they understand how inefficient their idea really was.
It's most effective when the decision maker has personally experienced the negative consequences of a particular idea, but helping them imagine it is the next best thing. If imagining the consequences of the decision is not enough, it may be possible to implement a solution on a trial basis without a backout plan. This allows only minimal loss to be incurred until the decision maker realizes the downside. The actual experience or realistic imagining can help make the costs, risks, and unintended consequences more "real" or more concrete to the decision maker.
Associate Idea to Similar Ideas Whose Problems are Well Known
It's often the case that decision makers know about poor previous decisions and their negative results, but they may not realize the relevance of that previous decision to the current decision. Developers can connect the two decisions and draw parallels between them. This can make it easier for the decision maker to identify the true costs, risks, and unintended consequences of the pending decision because the similar negative consequences of a similar decision made previously may now be known.
Enlist Recognized Experts
If the significance of a decision warrants it, it may be advisable to bring in a colleague who is a recognized guru or expert in the particular area to provide credibility to your argument. Such outside influence will be most effective if the person brought in has real life experience with something similar to the decision being made.
Avoid Hyperbole
Too much drama or exaggeration can doom chances of stopping a poor decision. The decision maker is more likely to dismiss the objections when they are obviously exaggerated. If a decision maker believes one has exaggerated in the past, he or she cannot be blamed for thinking that the same person is exaggerating again.
Not All Bad Decisions are Equal
Some bad decisions have more significant negative consequences than others. Because of this, not every decision deserves an equal challenge. The person who challenges every potential decision is more likely to be ignored when objecting to a really bad idea and dismissed as just a complainer. This is the "pick your battles" principle.
Assess Negatives and Positives of Major Decisions
Even when we are unable to avoid being subject to another's poor decision, we can potentially improve our own future by gently pointing out the negatives of the current decision. Although it's tempting to turn this into an "I told you so" session, what we really want is for the person who made the poor decision to realize their own error and to realize the value of our experience. It seems to be human nature to want to say "I told you so," but it's even more welcome when that doesn't need to be explicitly stated because everyone knows you did without you saying it. Making sure an objection to a really bad decision was made and acknowledged before everyone else realized its negative impact helps build this credibility and people will be more likely to listen carefully to your opinion the next time.
Recognize Own Deficiencies
It is also important to realize that everyone makes mistakes and everyone is limited based on lack of experience or knowledge in certain areas. Especially in the case where peers do not seem to agree with our position, we should ask ourselves, "Am I the one with the bad idea here?"
Not All Decisions Are All Technical
Perhaps one of the most difficult principles for we developers to accept is that not all decisions are made on a purely technical basis. We can argue as much as we want about the technical merits of something, but many other factors play into decisions. There are times when those seeing the bigger picture might make a technical decision we don't like for a real or perceived greater good.
One of the things that makes this difficult is that there seems to be a relatively small percentage of people who can adeptly weave technical aspects of a particular decision with the many non-technical aspects of the same decision. The technical person has a difficult time seeing how anyone could decide anything but the best technical solution and the non-technical person wonders how the technical person cannot see the overwhelming need for their decision to be applied.
It is an impasse like this that makes a good technical manager a significant boon. A good technical manager with technical background combined with good business and other skills can help mediate difficult decisions and provide some expert-based credibility to the decision.
Another thing that can help with this is when the technically minded folks attempt to understand the consequences of making a major decision purely on technical grounds. Just as decision makers who make bad technical decisions should need to live with their decisions, so should technically minded people who make poor non-technical decisions. Better than suffering the negative consequences is to think them through before making the decision.
Unpleasant Does Not Mean Poor or Bad
Sometimes, we have to do tasks that may not be our favorite task or may not be the most pleasant of tasks. This doesn't mean they are a result of a poor decision. There are times when we have to do certain tasks to get the job done or accomplish a certain goal that simply are not fun. However, if tasks are overly wasteful or demotivating with no real value or insufficient value to justify their cost, then we are talking about a bad or poor decision. Often the worst decisions are those for which there are some elements of "good," but these elements are outweighed by the bad if the decision maker will look closely enough at the likely obvious and unintentional consequences.
Leave the Situation
In the most severe cases of a pending poor decision, when all else fails, it may be advisable to remove oneself from the situation entirely. If the results of the decision are highly likely to lead to significant negative consequences that the decision maker does not have to deal with, it may be best for the potentially affected developer to make sure that he or she will not be the victim of the decision either. Removing oneself from the situation may be as easy as working on a different part of the project.
It's Easier to Choose Poorly When It Impacts Someone Else
The decisions that I have been most disappointed with and most frustrated with in my career have generally been made by people who don't have to live with the consequences of the decision. It's all too easy to avoid the effort involved in researching an issue and thinking about the wide range of choices and associated consequences (obvious and unintended) when one knows that he or she is not the one who suffers from being not putting in the requisite labor.
A colleague recently told me a story that reminds me that this is human nature. His in-laws planned to live with him for a short period of time while they looked for and purchased a new home in the area. He had suggested that they should rent PODS or equivalent to store the majority of their stuff in while living with him. His reasoning was that then they could load the PODS from their former house, have them delivered to the new house when it was purchased, and unload from the PODS to the new house. His mother-in-law, however, thought it was a better idea to move all the stuff from their old house to my colleague's house and then from my colleague's house to their new house. For her, this was a cheaper solution and it did not cost her anything because her son-in-laws would do all the moving in all cases. In other words, she had a choice of no cost (monetary or effort) versus a choice with monetary cost and so it was an obvious better deal for her to have her son-in-laws put extra effort into moving her stuff around. My guess is that if she had to do the moving, the rental price wouldn't look so bad after all (especially given the fact that they weren't paying rent anyway while living with the daughter and son-in-law). Meanwhile, her son-in-law colleague of mine, who was affected by her plan, was seriously considering simply paying for the PODS costs for his in-laws stuff because that decision benefited him.
When we don't have to live with the consequences of our decisions, it changes what we think is the best decision. I contend that we will generally make the best decisions when we have a stake in the outcome. When we envision how we would implement a decision ourselves, we start to realize more fully how good or bad the decision is.
Conclusion
There are few things more frustrating to a developer than being the victim of particularly poor decisions whose negative consequences are obvious to everyone but the decision maker. Assuming that the decision maker really has the organization's or client's best interests at heart, one important step to helping that person make a better decision is to help that person better understand how the organization or client is severely and negatively impacted by that decision. In cases where the decision maker only cares about himself or herself, it probably won't matter how bad the consequences are if he or she will not be affected by those consequences.
I think most people would agree that decisions and plans are best implemented when the people who must implement them take ownership of the decision. Therefore, it's fairly obvious that decision makers should get buy-in from the would-be owners of the decision's implementation. When decision makers don't get buy-in from those implementing the decision, the implementation may be found lacking. Getting buy-in from the implementers of a decision is also important because the very process of doing so may help the decision maker make a better, more informed decision.
Most decision-makers (managers, leads, customers) want to succeed and are trying to make good decisions. The problem is that they may lack a full understanding of the total costs, the risks. and the unintended consequences of a particular decision. It it sometimes sufficient to point out the total costs, the risks and the potential unintended consequences of the decision to head the poor decision off. Unfortunately, expressed risks, costs, and unintended consequences are often dismissed as overstated or not likely to be incurred.
In the remainder of this post, I look at steps that can be taken to attempt to stop or reduce poor decisions from having long-term adverse negative impacts on success.
Help or Allow the Decision Maker to Taste the Idea
A group of fellow developers and I stopped a particularly bad idea from being implemented when we helped the management team making the decision to visualize the true costs (time and schedule) of the decision. As they envisioned themselves implementing this onerous approach, they realized what we had been trying to tell them: their idea sounded good at first, but was very inefficient when considering the realities of the tools we had at the time. Only when they pictured themselves waiting on this tool to run did they understand how inefficient their idea really was.
It's most effective when the decision maker has personally experienced the negative consequences of a particular idea, but helping them imagine it is the next best thing. If imagining the consequences of the decision is not enough, it may be possible to implement a solution on a trial basis without a backout plan. This allows only minimal loss to be incurred until the decision maker realizes the downside. The actual experience or realistic imagining can help make the costs, risks, and unintended consequences more "real" or more concrete to the decision maker.
Associate Idea to Similar Ideas Whose Problems are Well Known
It's often the case that decision makers know about poor previous decisions and their negative results, but they may not realize the relevance of that previous decision to the current decision. Developers can connect the two decisions and draw parallels between them. This can make it easier for the decision maker to identify the true costs, risks, and unintended consequences of the pending decision because the similar negative consequences of a similar decision made previously may now be known.
Enlist Recognized Experts
If the significance of a decision warrants it, it may be advisable to bring in a colleague who is a recognized guru or expert in the particular area to provide credibility to your argument. Such outside influence will be most effective if the person brought in has real life experience with something similar to the decision being made.
Avoid Hyperbole
Too much drama or exaggeration can doom chances of stopping a poor decision. The decision maker is more likely to dismiss the objections when they are obviously exaggerated. If a decision maker believes one has exaggerated in the past, he or she cannot be blamed for thinking that the same person is exaggerating again.
Not All Bad Decisions are Equal
Some bad decisions have more significant negative consequences than others. Because of this, not every decision deserves an equal challenge. The person who challenges every potential decision is more likely to be ignored when objecting to a really bad idea and dismissed as just a complainer. This is the "pick your battles" principle.
Assess Negatives and Positives of Major Decisions
Even when we are unable to avoid being subject to another's poor decision, we can potentially improve our own future by gently pointing out the negatives of the current decision. Although it's tempting to turn this into an "I told you so" session, what we really want is for the person who made the poor decision to realize their own error and to realize the value of our experience. It seems to be human nature to want to say "I told you so," but it's even more welcome when that doesn't need to be explicitly stated because everyone knows you did without you saying it. Making sure an objection to a really bad decision was made and acknowledged before everyone else realized its negative impact helps build this credibility and people will be more likely to listen carefully to your opinion the next time.
Recognize Own Deficiencies
It is also important to realize that everyone makes mistakes and everyone is limited based on lack of experience or knowledge in certain areas. Especially in the case where peers do not seem to agree with our position, we should ask ourselves, "Am I the one with the bad idea here?"
Not All Decisions Are All Technical
Perhaps one of the most difficult principles for we developers to accept is that not all decisions are made on a purely technical basis. We can argue as much as we want about the technical merits of something, but many other factors play into decisions. There are times when those seeing the bigger picture might make a technical decision we don't like for a real or perceived greater good.
One of the things that makes this difficult is that there seems to be a relatively small percentage of people who can adeptly weave technical aspects of a particular decision with the many non-technical aspects of the same decision. The technical person has a difficult time seeing how anyone could decide anything but the best technical solution and the non-technical person wonders how the technical person cannot see the overwhelming need for their decision to be applied.
It is an impasse like this that makes a good technical manager a significant boon. A good technical manager with technical background combined with good business and other skills can help mediate difficult decisions and provide some expert-based credibility to the decision.
Another thing that can help with this is when the technically minded folks attempt to understand the consequences of making a major decision purely on technical grounds. Just as decision makers who make bad technical decisions should need to live with their decisions, so should technically minded people who make poor non-technical decisions. Better than suffering the negative consequences is to think them through before making the decision.
Unpleasant Does Not Mean Poor or Bad
Sometimes, we have to do tasks that may not be our favorite task or may not be the most pleasant of tasks. This doesn't mean they are a result of a poor decision. There are times when we have to do certain tasks to get the job done or accomplish a certain goal that simply are not fun. However, if tasks are overly wasteful or demotivating with no real value or insufficient value to justify their cost, then we are talking about a bad or poor decision. Often the worst decisions are those for which there are some elements of "good," but these elements are outweighed by the bad if the decision maker will look closely enough at the likely obvious and unintentional consequences.
Leave the Situation
In the most severe cases of a pending poor decision, when all else fails, it may be advisable to remove oneself from the situation entirely. If the results of the decision are highly likely to lead to significant negative consequences that the decision maker does not have to deal with, it may be best for the potentially affected developer to make sure that he or she will not be the victim of the decision either. Removing oneself from the situation may be as easy as working on a different part of the project.
It's Easier to Choose Poorly When It Impacts Someone Else
The decisions that I have been most disappointed with and most frustrated with in my career have generally been made by people who don't have to live with the consequences of the decision. It's all too easy to avoid the effort involved in researching an issue and thinking about the wide range of choices and associated consequences (obvious and unintended) when one knows that he or she is not the one who suffers from being not putting in the requisite labor.
A colleague recently told me a story that reminds me that this is human nature. His in-laws planned to live with him for a short period of time while they looked for and purchased a new home in the area. He had suggested that they should rent PODS or equivalent to store the majority of their stuff in while living with him. His reasoning was that then they could load the PODS from their former house, have them delivered to the new house when it was purchased, and unload from the PODS to the new house. His mother-in-law, however, thought it was a better idea to move all the stuff from their old house to my colleague's house and then from my colleague's house to their new house. For her, this was a cheaper solution and it did not cost her anything because her son-in-laws would do all the moving in all cases. In other words, she had a choice of no cost (monetary or effort) versus a choice with monetary cost and so it was an obvious better deal for her to have her son-in-laws put extra effort into moving her stuff around. My guess is that if she had to do the moving, the rental price wouldn't look so bad after all (especially given the fact that they weren't paying rent anyway while living with the daughter and son-in-law). Meanwhile, her son-in-law colleague of mine, who was affected by her plan, was seriously considering simply paying for the PODS costs for his in-laws stuff because that decision benefited him.
When we don't have to live with the consequences of our decisions, it changes what we think is the best decision. I contend that we will generally make the best decisions when we have a stake in the outcome. When we envision how we would implement a decision ourselves, we start to realize more fully how good or bad the decision is.
Conclusion
There are few things more frustrating to a developer than being the victim of particularly poor decisions whose negative consequences are obvious to everyone but the decision maker. Assuming that the decision maker really has the organization's or client's best interests at heart, one important step to helping that person make a better decision is to help that person better understand how the organization or client is severely and negatively impacted by that decision. In cases where the decision maker only cares about himself or herself, it probably won't matter how bad the consequences are if he or she will not be affected by those consequences.
I think most people would agree that decisions and plans are best implemented when the people who must implement them take ownership of the decision. Therefore, it's fairly obvious that decision makers should get buy-in from the would-be owners of the decision's implementation. When decision makers don't get buy-in from those implementing the decision, the implementation may be found lacking. Getting buy-in from the implementers of a decision is also important because the very process of doing so may help the decision maker make a better, more informed decision.
$15 Off Today Only at Manning
Manning is offering $15 off any "pbook" (printed book), "ebook" (electronic book), or MEAP (Manning Early Access Program) for today only (27 December 2010). Use the code dotd1227 at the Manning site to get this discount. According to the Deal of the Day e-mail message I received, the "$15 discount on any purchase expires at midnight ET (GMT - 5:00) tonight!"
Thursday, December 23, 2010
Using Generic 'log' Methods in Java Logging
When developing Java applications, it is easy to get used to invoking logging on the provided logger via its log level-specific methods. For example, Log4j's Logger provides methods such as Logger.info(Object), Logger.warn(Object), Logger.error(Object), and Logger.fatal(Object) and java.util.logging's Logger provides methods such as Logger.info(String), Logger.warning(String), and Logger.severe(String). These methods have names that explicitly convey the level at which the message is logged and often work well. However, there are situations when the code can be cleaner and the logging more efficient when a more generic logging method is used. In this blog post, I look at Log4j's overloaded Logger.log methods and java.util.logging's overloaded Logger.log methods.
The next example is a little contrived, but should suffice. It demonstrates logging at a specific level (INFO in this case) using
Code Listing One
The logging statement in the above code will always log at INFO level if it logs at all (only logs if INFO-level logging is turned on). This might be satisfactory in most cases, but one might want it to be a higher level if the divisor is zero. Before getting to that, though, I want to take a side detour and look at NetBeans 6.9's hint that highlights the line of code above with the log statement. The next screen snapshot shows the above code again, but this time as it is rendered in the NetBeans editor window with the logging line highlighted with a hint.

This particular hint (Inefficient use of string concatenation in logger) is not one of the hints that I highlighted in my earlier post Seven Indispensable NetBeans Java Hints, but I'll follow its recommendation here. When I select the option to have NetBeans automatically address this hint ("Convert string concatenation to a message template"), it changes the code as shown in the next two screen captures and code listing.


The code has been changed by NetBeans 6.9 to that shown in the next code listing.
Code Listing Two
Accepting the NetBeans hint's automatic fix changed the explicit call to
To illustrate another reason for using the more generic log method in some cases, I go back to the code as originally listed in Code Listing One with a twist. In Code Listing Three, I have modified that code to change its log level depending on runtime information.
Code Listing Three
In the above code, the same statement is potentially logged at different levels depending on a runtime condition. Suppose that the application was run with logging only enabled for warning and more significant log levels. In such a hypothetical situation, only the case with a divisor of zero would be logged and the "normal" cases would not. This might be intentional because only the zero divisor situation might require typical logging. The code could be slightly improved by avoiding duplicate String literals. This is shown in Code Listing Four.
Code Listing Four
Code Listing Four makes it more obvious that the String is the same in both logging cases. Incidentally, it also is rendered without NetBeans hint because the string concatenation is not within the logging statement.
Changing the log call to use the generic Logger.log allows the developer to only need to specify the log statement once. This is demonstrated in Code Listing Five.
Code Listing Five
Code Listing Five demonstrates the ability to set the log level at runtime with a single conditional ternary operator and then only have one log statement that will log at the appropriate level given runtime differentiation.
So far, the discussion has centered around
Code Listing Six
The code for the Log4j example is almost identical to the
Having a dynamic log level can also be useful when writing logging guards. There are numerous cases where it is most efficient to check if a given log level is applicable before trying to log to that level. This is especially the case when long-running logic is necessary to build up the String to be logged and can include explicitly or implicitly called toString() implementations.
I will be using the nonsensical
Code Listing Seven: SlowToString.java
In this extreme case, logging of any messages that invoke
Code Listing Eight
Developers new to Java might think that the delay of
Code Listing Nine
Even explicitly setting the logging level to be SEVERE is not sufficient to prevent the
Code Listing Ten
When Code Listing Ten is executed, it will only bother trying to build up the long-running
Code Listing Eleven
Use of the more generic log method as demonstrated in Code Listing Eleven allows the guard and the logging statement itself to remain synchronized in terms of level. When the developer wishes to change the level of this particular logging, he or she can do so by changing only one line (where the logLevel variable is set). This is even potentially more powerful when one considers combining this with the ability to set this level dynamically as shown earlier in this post. The guards and the individual logging statements can potentially be controlled in a synchronized fashion based on dynamic runtime considerations. That's pretty powerful stuff!
All of the above discussions apply to Log4j as much as they apply to
Code Listing Twelve provides a rough Log4j equivalent to the
Code Listing Twelve
Because Log4j's logging methods accept an
Beyond Log4j and java.util.logging
I have focused on Log4j and
Conclusion
In many situations, the developer knows what at which level logging needs to occur and, if the logged string is literal or quick to generate, use of the level-specific logging methods may be easiest, cleanest, and most readable. However, when the level of logging is more dependent on runtime conditions than development time conditions or when guards need to be synchronized with the log method(s) invoked within the guard, the ability to log generically to a runtime-provided level allows the code to be more efficient, more maintainable, and more consistent.
Additional Reading
I thought of writing this post based on recent publication of blogs related to effective logging practices. These included The Dark Art of Logging (discusses importance of logging at appropriate level and using logging guards) and Logging Do's and Dont's (tightly associated with use of SLF4J).
The next example is a little contrived, but should suffice. It demonstrates logging at a specific level (INFO in this case) using
java.util.logging.Code Listing One
/**
* Divide the provided dividend by the provided divisor and return the quotient.
*
* @param dividend Number to be divided.
* @param divisor Number by which dividend is to be divided.
* @return Quotient of dividend divided by divisor.
*/
private double divide(final double dividend, final double divisor)
{
final double quotient = dividend / divisor;
LOGGER.info("Quotient of " + dividend + " divided by " + divisor + " is " + quotient + ".");
return quotient;
}
The logging statement in the above code will always log at INFO level if it logs at all (only logs if INFO-level logging is turned on). This might be satisfactory in most cases, but one might want it to be a higher level if the divisor is zero. Before getting to that, though, I want to take a side detour and look at NetBeans 6.9's hint that highlights the line of code above with the log statement. The next screen snapshot shows the above code again, but this time as it is rendered in the NetBeans editor window with the logging line highlighted with a hint.

This particular hint (Inefficient use of string concatenation in logger) is not one of the hints that I highlighted in my earlier post Seven Indispensable NetBeans Java Hints, but I'll follow its recommendation here. When I select the option to have NetBeans automatically address this hint ("Convert string concatenation to a message template"), it changes the code as shown in the next two screen captures and code listing.


The code has been changed by NetBeans 6.9 to that shown in the next code listing.
Code Listing Two
/**
* Divide the provided dividend by the provided divisor and return the quotient.
*
* @param dividend Number to be divided.
* @param divisor Number by which dividend is to be divided.
* @return Quotient of dividend divided by divisor.
*/
private double divide(final double dividend, final double divisor)
{
final double quotient = dividend / divisor;
LOGGER.log(Level.INFO, "Quotient of {0} divided by {1} is {2}.", new Object[]{dividend, divisor, quotient});
return quotient;
}
Accepting the NetBeans hint's automatic fix changed the explicit call to
Logger.info to instead call the more generic Logger.log method. In this case, a driving reason for the change seems to be the availability in the Logger.log method to support a message String with object parameters to the String. Although it is not surprising that NetBeans would change from the explicit and specific info method to the more generic log method to take advantage of the message String with object parameters, that is not the only reason one might prefer the more generic log method.To illustrate another reason for using the more generic log method in some cases, I go back to the code as originally listed in Code Listing One with a twist. In Code Listing Three, I have modified that code to change its log level depending on runtime information.
Code Listing Three
/**
* Divide the provided dividend by the provided divisor and return the quotient.
*
* @param dividend Number to be divided.
* @param divisor Number by which dividend is to be divided.
* @return Quotient of dividend divided by divisor.
*/
private double divide(final double dividend, final double divisor)
{
final double quotient = dividend / divisor;
if (Double.doubleToLongBits(divisor) == 0)
{
LOGGER.warning("Quotient of " + dividend + " divided by " + divisor + " is " + quotient + ".");
}
else
{
LOGGER.info("Quotient of " + dividend + " divided by " + divisor + " is " + quotient + ".");
}
return quotient;
}
In the above code, the same statement is potentially logged at different levels depending on a runtime condition. Suppose that the application was run with logging only enabled for warning and more significant log levels. In such a hypothetical situation, only the case with a divisor of zero would be logged and the "normal" cases would not. This might be intentional because only the zero divisor situation might require typical logging. The code could be slightly improved by avoiding duplicate String literals. This is shown in Code Listing Four.
Code Listing Four
/**
* Divide the provided dividend by the provided divisor and return the quotient.
*
* @param dividend Number to be divided.
* @param divisor Number by which dividend is to be divided.
* @return Quotient of dividend divided by divisor.
*/
private double divide(final double dividend, final double divisor)
{
final double quotient = dividend / divisor;
final String message = "Quotient of " + dividend + " divided by " + divisor + " is " + quotient + ".";
if (Double.doubleToLongBits(divisor) == 0)
{
LOGGER.warning(message);
}
else
{
LOGGER.info(message);
}
return quotient;
}
Code Listing Four makes it more obvious that the String is the same in both logging cases. Incidentally, it also is rendered without NetBeans hint because the string concatenation is not within the logging statement.
Changing the log call to use the generic Logger.log allows the developer to only need to specify the log statement once. This is demonstrated in Code Listing Five.
Code Listing Five
/**
* Divide the provided dividend by the provided divisor and return the quotient.
*
* @param dividend Number to be divided.
* @param divisor Number by which dividend is to be divided.
* @return Quotient of dividend divided by divisor.
*/
private double divide(final double dividend, final double divisor)
{
final double quotient = dividend / divisor;
final String message = "Quotient of " + dividend + " divided by " + divisor + " is " + quotient + ".";
final Level logLevel =
Double.doubleToLongBits(divisor) == 0
? Level.WARNING
: Level.INFO;
LOGGER.log(logLevel, message);
return quotient;
}
Code Listing Five demonstrates the ability to set the log level at runtime with a single conditional ternary operator and then only have one log statement that will log at the appropriate level given runtime differentiation.
So far, the discussion has centered around
java.util.logging. However, Log4j provides similar support both for methods with name specific to a logging level and for more general logging methods based on a provided log level. Code Listing Six is shown next and provides the Log4j equivalent of Code Listing Five.Code Listing Six
/**
* Divide the provided dividend by the provided divisor and return the quotient.
*
* @param dividend Number to be divided.
* @param divisor Number by which dividend is to be divided.
* @return Quotient of dividend divided by divisor.
*/
private double divide(final double dividend, final double divisor)
{
final double quotient = dividend / divisor;
final String message = "Quotient of " + dividend + " divided by " + divisor + " is " + quotient + ".";
final Level logLevel =
Double.doubleToLongBits(divisor) == 0
? Level.WARN
: Level.INFO;
LOGGER.log(logLevel, message);
return quotient;
}
The code for the Log4j example is almost identical to the
java.util.logging example. One of the only differences is that java.util.logging's warning-level constant is Level.WARNING while Log4j's similar constant is Level.WARN. I obviously also had to import different Logger and Level classes in both cases.Having a dynamic log level can also be useful when writing logging guards. There are numerous cases where it is most efficient to check if a given log level is applicable before trying to log to that level. This is especially the case when long-running logic is necessary to build up the String to be logged and can include explicitly or implicitly called toString() implementations.
I will be using the nonsensical
SlowToString class (shown in Code Listing Seven) to illustrate the value of logging guards and how to use dynamic resolution of logging level in conjunction with such guards. Although the SlowToString class is nonsense, it simulates the potential inefficiencies of logging String representations of objects with complex toString() methods.Code Listing Seven: SlowToString.java
/**
* Class with intentionally slow toString() implementation.
*
* @author Dustin
*/
public class SlowToString
{
@Override
public String toString()
{
try
{
Thread.sleep(Integer.MAX_VALUE);
}
catch (InterruptedException threadEx)
{
// this is really bad; don't do this!!!
}
return "";
}
}
In this extreme case, logging of any messages that invoke
SlowToString's toString() method will be held up a painfully long time. Code Listing Eight shows a piece of code that would suffer from this with java.util.logging.Code Listing Eight
/**
* Demonstrate logging of object with slow toString() implementation.
*/
private void demonstrateLoggingGuard()
{
final SlowToString slow = new SlowToString();
LOGGER.finer(slow.toString()); // toString must be explicitly called
}
Developers new to Java might think that the delay of
SlowToString's toString() method will only be incurred if logging at FINER level is enabled. Unfortunately, that is not the case. The toString() above will always be invoked regardless of level. In fact, even code as shown in Code Listing Nine will have the same unsatisfactory delay.Code Listing Nine
/**
* Demonstrate logging of object with slow toString() implementation.
*/
private void demonstrateLoggingGuard()
{
final SlowToString slow = new SlowToString();
LOGGER.setLevel(Level.SEVERE);
LOGGER.finer(slow.toString()); // toString must be explicitly called
}
Even explicitly setting the logging level to be SEVERE is not sufficient to prevent the
SlowToString.toString() method from being invoked. A logging guard is needed. This is demonstrated in Code Listing Ten for this java.util.logging-based example.Code Listing Ten
/**
* Demonstrate logging of object with slow toString() implementation.
*/
private void demonstrateLoggingGuard()
{
final SlowToString slow = new SlowToString();
if (LOGGER.isLoggable(Level.FINER))
{
LOGGER.finer(slow.toString()); // toString must be explicitly called
}
}
When Code Listing Ten is executed, it will only bother trying to build up the long-running
toString() implementation if the logging level is set to at least FINER. There's a maintenance issue with this code, however. One could, especially if the code base was much larger, change one level (either the logging statement or the guard) without changing the other. If the guard was changed to a less severe log level (finest), the log statement would never get run despite it still using the "finer" method. That is likely to be less of a problem than the other possibility: if the guard is more restrictive (say INFO), then the performance cost would be incurred anyway despite the guard and even though nothing would actually get logged. The solution for this to be more maintainable is to set the log level once and then use that same set log level for the guard and for the logging statement itself. This is demonstrated in Code Listing Eleven.Code Listing Eleven
/**
* Demonstrate logging of object with slow toString() implementation.
*/
private void demonstrateLoggingGuard()
{
final SlowToString slow = new SlowToString();
final Level logLevel = Level.FINER;
if (LOGGER.isLoggable(logLevel))
{
LOGGER.log(logLevel, slow.toString()); // toString must be explicitly called
}
}
Use of the more generic log method as demonstrated in Code Listing Eleven allows the guard and the logging statement itself to remain synchronized in terms of level. When the developer wishes to change the level of this particular logging, he or she can do so by changing only one line (where the logLevel variable is set). This is even potentially more powerful when one considers combining this with the ability to set this level dynamically as shown earlier in this post. The guards and the individual logging statements can potentially be controlled in a synchronized fashion based on dynamic runtime considerations. That's pretty powerful stuff!
All of the above discussions apply to Log4j as much as they apply to
java.util.logging. Log4j has guard methods with specific levels in their names just as it does for the logging methods. For example, it has methods like Logger.isTraceEnabled(), Logger.isInfoEnabled(), and Logger.isDebugEnabled(). Fortunately, Log4j also provides a generic form of the guard method similar to that provided by java.util.logging. Log4j's Logger.isEnabledFor(Priority) method can be used as a generic logging guard.Code Listing Twelve provides a rough Log4j equivalent to the
java.util.logging example.Code Listing Twelve
/**
* Demonstrate logging of object with slow toString() implementation.
*/
private void demonstrateLoggingGuard()
{
final SlowToString slow = new SlowToString();
final Level logLevel = Level.DEBUG;
if (LOGGER.isEnabledFor(logLevel))
{
LOGGER.log(logLevel, slow); // Look Ma! No toString() required!
}
}
Because Log4j's logging methods accept an
Object rather than a String, the toString() method does not need to be explicitly called for Log4j. This means that the toString() might even be called without the developer realizing it. Using Log4j's Logger.isEnabledFor(Priority) method allows the developer to again synchronize the level of the guard with the level of the message or messages being logged.Beyond Log4j and java.util.logging
I have focused on Log4j and
java.util.logging in this post. Although these are dominant Java logging frameworks, many Java developers like to use higher level logging APIs such as Apache Commons Logging or Simple Logging Facade for Java (SLF4J). I typically use one of the frameworks (Log4j or java.util.logging) directly, so I'm not familiar with these other frameworks. That being stated, it appears that Apache Commons Logging's Log interface does not provide for generic logging methods or generic guard methods. As far as I can tell, SLF4J's Logger interface similarly does not support generic logging and guard methods either. If anyone knows differently than this, please let me know via feedback comment. Because SLF4J and Apache Commons Logging are largely "wrappers"/"facades" for Log4j and java.util.logging, it seems that the generic support for logging and guard checking provided by those underlying libraries could be "passed through."Conclusion
In many situations, the developer knows what at which level logging needs to occur and, if the logged string is literal or quick to generate, use of the level-specific logging methods may be easiest, cleanest, and most readable. However, when the level of logging is more dependent on runtime conditions than development time conditions or when guards need to be synchronized with the log method(s) invoked within the guard, the ability to log generically to a runtime-provided level allows the code to be more efficient, more maintainable, and more consistent.
Additional Reading
I thought of writing this post based on recent publication of blogs related to effective logging practices. These included The Dark Art of Logging (discusses importance of logging at appropriate level and using logging guards) and Logging Do's and Dont's (tightly associated with use of SLF4J).
Subscribe to:
Comments (Atom)